Has the Research Excellence Framework changed how we write papers? The case of mathematics education
This blogpost is written by Prof Matthew Inglis, Professor of Mathematical Cognition and the co-director of the Centre for Mathematical Cognition and the Centre for Early Mathematics Learning, Loughborough University. Typeset by Dr Beth Woollacott.
In this blogpost, Matthew addresses the question:
What effect has the Research Excellence Framework (REF) had on academic writing in the UK?
Matthew explores the hypothesis that British academics, as a result of the REF and its definition of research quality, tend to explicitly claim – or perhaps overclaim – that their findings are original and significant.
Background and motivation
The background to this concerns an article my colleagues and I recently published in the British Educational Research Journal (Inglis, Foster, Lortie-Forgues & Stokoe, 2024). We sought to understand the criteria used to evaluate the quality of manuscripts by the education subpanel of REF2021.
The REF is the process by which the government evaluates the quality of each university’s research, with the aim of allocating research funding according to some notion of ‘quality’, which is formally defined in terms of “originality, significance and rigour”. The 2021 exercise involved 34 different disciplines, or ‘subpanels’, to which universities could decide to submit returns, education being one such subpanel. Submissions were made up of various things, but the most important was ‘outputs’. Each submitting ‘unit’ (normally a university department), selected a number of their best outputs (journal articles, books, etc) that were published during the assessment period (the quantity needed varied by staff numbers), and these were evaluated by leading academics from the discipline. Each output was assigned a quality score on a five-point scale, from 4* (world-leading) to 0* (below nationally recognised).
Our goal in the BERJ study (Inglis et al., 2024) was to investigate the REF’s peer review process. Although the peer review outcomes of individual outputs are not published, the collated outcomes for units are. For instance, we know that 37.1% of the outputs submitted as a part of Loughborough’s education return were deemed to be of 4* quality, that 34.3% were deemed to be of 3* quality, and so on. These numbers can be conveniently summarised with a Grade Point Average (the linear combination of the profile percentages with the quality ratings), which for Loughborough was 3.056. Because these quality profiles are available for each submission, by studying the issues/methods that each submission returned outputs about, it is possible to make inferences about those which were associated with high scores in the REF, and those that are associated with low scores.
Nevertheless, there is a methodological challenge to such work. Because 5295 outputs were submitted to the education subpanel of REF2021, it is not feasible for a research team to read and code them all by hand to identify the issues they discuss and the methods they use. Instead, we used a technique known as latent Dirichlet allocation topic modelling, a machine learning method which allows inferences to be made about the content of a large number of texts. As we stated in the paper:
“The method takes a large collection of unstructured texts and studies the words they contain. For instance, if a document contains many instances of the words ‘sofa’, ‘table’ and ‘armchair’, we might infer that the document is, to some extent at least, about furniture. Formally, a topic is defined to be a probability distribution over words. So, a furniture topic would associate high probabilities to words related to furniture (‘sofa’, ‘table’, ‘armchair’) and low probabilities to words unrelated to furniture (‘biscuit’, ‘fishing’, ‘stockbroker’).”
Inglis et al., 2024, p. 2498
We fitted a 35-topic model to the 4290 English-language journal articles submitted to the education subpanel in 2021 (the remaining 1005 outputs were either written in a non-English language or were not journal articles and so less accessible). Having identified a set of topics, we were able to describe the contents of each of these 4290 articles as a linear combination of topics. For instance, our model suggested that my paper “How mathematicians obtain conviction: Implications for mathematics instruction and research on epistemic cognition” (Weber, Inglis & Mejia-Ramos, 2014) was 54% about mathematics, 21% about methodologies (a topic we called ‘methodological depth’) and 17% about the philosophy of education.
Having calculated these linear combinations of all the journal articles submitted to the education subpanel, we were able to calculate the makeup of the ‘composite mean paper’ for each unit. This is an imagined paper formed of the mean topic weights for each of the actual papers submitted by that unit. For instance, we found that 17.4% of the words from the Open University’s composite mean paper came from the Technology Enhanced Learning topic and that 14.7% of the words from Loughborough’s composite mean paper came from the mathematics topic. These numbers are highly consistent with our impressions of the research foci of these respective departments, providing a degree of face validity to our model.
Intriguingly, we found that a remarkably high proportion – 84.1% – of the variance in units’ output GPAs could be explained by the makeup of their composite mean papers. Because we were also able to use our model to successfully predict the output GPAs from REF2014 (the previous, and completely independent, exercise), we argued that this high figure could not solely be attributed to overfitting or other statistical artefacts. Studying the coefficients associated with each of the topics in the model revealed that units that returned more interview-based work typically received lower scores, and those which returned more analyses of large-scale data and meta-analyses typically received higher scores.
My goal in this blogpost is to discuss another of the topics we identified in the BERJ paper, Topic 20, which we named Claims of Significance. We justified this as follows:
“Topic 20 was characterised by words such as ‘first’, ‘significant’, ‘findings’, ‘specific’, ‘influence’, ‘field’, ‘effects’, ‘find’, ‘differences’, ‘reflect’ and ‘significantly’. Unlike most other topics, there were few articles that had particularly high proportions of words from the topic. The largest was Baird et al.’s (2017) article ‘Rater accuracy and training group effects in Expert- and Supervisor-based monitoring systems’, which had 44% of its words from Topic 20. This article was notable for the emphasis made on asserting the originality and significance of the reported research. For instance, Baird et al. noted that their ‘study is the first to show instability across monitoring systems’ (p. 11), that it is ‘the first study to show this [result] as a general effect, rather than for a particular team, and [that] it is the first to use multilevel modelling to do so’ (p. 11). Furthermore, they argued that their results are ‘important findings, as face-to-face training and Supervisor-based monitoring systems are still the norm in many examination settings for practical reasons’ (p. 12).
In short, the paper attempted to make a particularly strong case for the originality and wider significance of its findings. No other paper had nearly as high a proportion of words from Topic 20 (the next highest was 23%), but all the papers with proportions over 20% also discussed the significance of their findings (e.g., they developed a wider theoretical framework or discussed the implications of their results for practice at length). For example, Gibbs and Elliott’s (2015) study of how teachers interpret terms such as ‘dyslexia’ described how their findings ‘provide a potential challenge to the value, meaning and impact of certain labels that may be used as “short-hand” descriptors for the difficulties that some children experience’ (p. 335). In contrast, when we studied papers which had 0% of words from Topic 20, we found instances of papers which made little attempt to draw wider implications. For example, Langdown et al.’s (2019) article ‘Acute effects of different warm-up protocols on highly skilled golfers’ drive performance’ provided compelling evidence for how golfers might improve their drives, but did not attempt to generalise to learning sporting skills outside of golf, or to learning more generally. We decided to name Topic 20 Claims of Significance.”
Perhaps unsurprisingly, given the REF’s definition of research quality (“originality, significance and rigour”), units which submitted papers that had higher proportions of their words from the Claims of Significance topic tended to receive higher output GPAs than those which did not. This effect was large: doubling the proportion of words from this topic was associated with an expected increase in GPA of 0.08. This was the fourth largest positive coefficient of all the 35 topics we identified.
There has been a great deal of reflection on whether the UK’s approach to research assessment is a good idea. For example, Donald Gillies has produced a detailed argument, drawing on ideas from the philosophy of science literature, which suggests that the REF harms research quality (Gillies, 2008). But here I want to explore another possible unintended consequence: has the REF’s definition of research quality changed how we write our papers? Specifically, might the REF have led to academics making more explicit claims, or possibly even exaggerated claims, about the originality and significance of their research?
So, has the REF’s definition of quality changed how academics write papers?
If this were true we might expect that academics based in the UK would write papers which contain explicit discussion of the originality and significance of the reported research. There are at least two reasonable comparison groups: academics based outside of the UK, and UK-based academics writing before the REF’s definition of research quality was introduced. Happily, the model from our BERJ paper provides a method by which this hypothesis can be explored. Specifically, if the REF has changed how UK academics write academic papers we would expect to see two main effects. First, we would expect that recent journal articles written by UK academics would, on average, have a higher proportion of words from the Claims of Significance topic than recent journal articles written by non-UK academics. Second, we would expect that this difference would not exist prior to the introduction of the REF’s definition of research quality as being “originality, significance and rigour”.
Looking at the evidence
To explore where there is evidence for these hypotheses, I obtained pdf copies of every article published in seven leading mathematics education research journals, as found by Williams and Leatham’s (2017) study, for two four-year periods: 2020-2023 and 2000-2003. These were Educational Studies in Mathematics (ESM), the Journal for Research in Mathematics Education (JRME), the Journal of Mathematical Behavior (JMB), the Journal of Mathematics Teacher Education (JMTE), Mathematical Thinking and Learning (MTL), Research in Mathematics Education (RME) and ZDM: Mathematics Education (ZDM). I excluded For the Learning of Mathematics (FLM), as it tends to publish a particular and atypical style of article, and so I was unconvinced that the BERJ model would be useful for analysing it. The period 2000-2003 was chosen as a comparator because, although the precursor to the REF (the Research Assessment Exercise, RAE) was in place during this period, it did not have an explicit definition of research. Rather panellists in RAE2001 were simply instructed to use their professional judgement to make assessments of quality “against international standards of excellence” (RAE2001, Guidance to Panel Chairs and Members: Criteria and Working Methods). The first time the criteria of “originality, significance and rigour” explicitly appeared in RAE documentation was for the 2008 (Johnston, 2008).
To identify mathematics education papers from these journals published during these periods I relied upon the OpenAlex database. Importantly, OpenAlex includes various metadata about each paper, including its type (article, book review, editorial etc), its authors (name, institution, country) and some information about its citation impact (including the field-weighted citation impact, FWCI, a measure of how many citations the paper has received, relative to the expected number of citations given the paper’s topic and age). The OpenAlex database is not perfect (many book reviews and editorials are categorised as articles, for example), and I attempted to clean these data manually as best as I could (i.e. by eliminating book reviews that had been misclassified by OpenAlex as articles), although I may not have succeeded with total accuracy.
In total I found 1870 articles indexed by OpenAlex suitable to be included in my analysis, 507 from the 2000s and 1363 from the 2020s. Of these 1870 articles 188 had at least one author based at a UK institution (98 from the 2000s, 90 from the 2020s). (In cases where the paper had authors from both the UK and outside the UK, it was classified as being a UK-authored paper, as I felt that any paper authored by a UK-based academic was likely to have been influenced by the REF criteria.)
These 1870 articles were converted to plain text using the UNIX pdftotext command (Poppler), and the model discussed in our BERJ paper was fitted. This allowed me to calculate the proportion of each articles’ words (after deleting ‘stop words’ like “the”, “is”, “a” etc) that came from each of the 35 topics, including the Claims of Significance topic.
The mean proportion of words from the Claims of Significance topic for papers from the 2000s and 2020s, split by whether the paper had a UK author or not, are shown in Table 1. Because topic proportions are highly non-normal, it is not clear that these means are the best way of summarising the four distributions. Given this, I have plotted histograms showing the full distributions in Figure 1. As these show, the large majority of papers have very few words from the Claims of Significance topic. In the 2000s this was true for papers written by both UK authors and non-UK authors. But by the 2020s, words from this topic were more common from both types of authors, but dramatically more so from UK-based authors.
| Era | UK Author | Not a UK author |
| 2000s | 0.000179 | 0.000292 |
| 2020s | 0.014919 | 0.004766 |
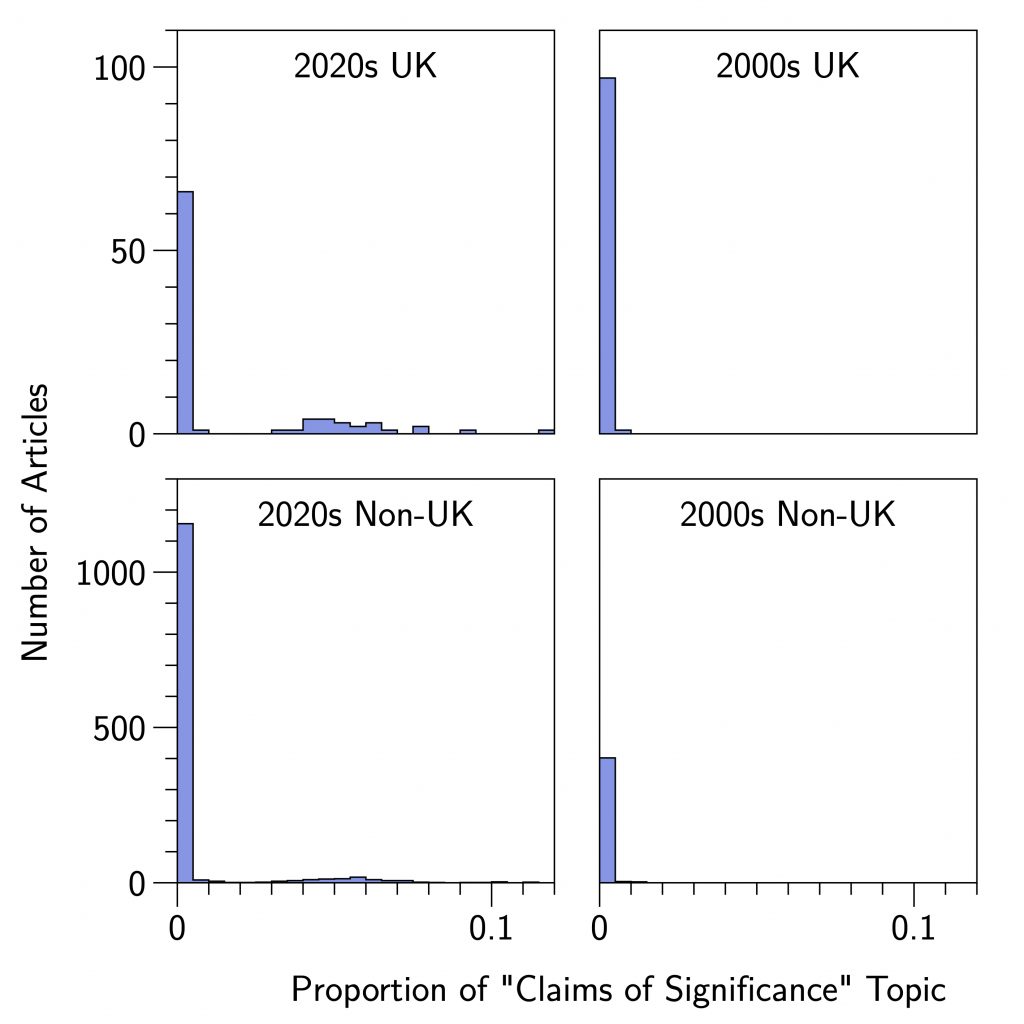
Unfortunately these data dramatically violate assumptions which underpin parametric statistical analyses, such as a traditional Analyses of Variance. Instead I adopted a randomisation test approach (Edgington & Onghena, 2007), running a two-way permutation Analysis of Variance with two factors (Era: 2000s, 2020s; Authorship: UK, non-UK) using the aovp command of the R package lmPerm (Permutation tests for linear models, Wheeler & Torchiano, 2022).
The findings
This analysis revealed a significant main effect of Authorship, p < .001, a significant main effect of Era, p < .001, and, critically, a significant Authorship×Era interaction effect, p < .001. In other words, these data show a pattern of results entirely consistent with the hypothesis that mathematics education academics from the UK have adapted how they write academic articles in response to the REF’s definition of research quality. (As a check to see if there was anything odd about the “non-UK” category, I repeated these analyses replacing the UK with the USA. This revealed no significant Authorship×Era interaction effect. In other words, there does seem to be something special about the UK.)
Might there be alternative accounts of these data, unrelated to the REF? One obvious possibility would be to suggest that mathematics education articles written by UK authors are in fact more original and significant than those written by non-UK authors, and that this difference has emerged at some point over the last 20 years. This possibility can be investigated (to some extent at least) by exploring the mean Field Weighted Citation Impacts of articles from the various categories. These data are shown in Table 2 and Figure 2. Again, given how skewed FWCI data are, I conducted a two-way permutation Analysis of Variance with two factors (Era: 2000s, 2020s; Authorship: UK, non-UK). This revealed no significant main effects or interactions (Era p = .067, Authorship p =.148, Authorship×Era p = .175). In other words, it seems implausible that the increase in Claims of Significance from UK authors can be attributed to an actual increase in the amount of significant research being conducted in the UK, at least as indexed by citation metrics.
| Era | UK Author | Not a UK Author |
| 2000s | 3.325 | 5.158 |
| 2020s | 3.977 | 4.360 |
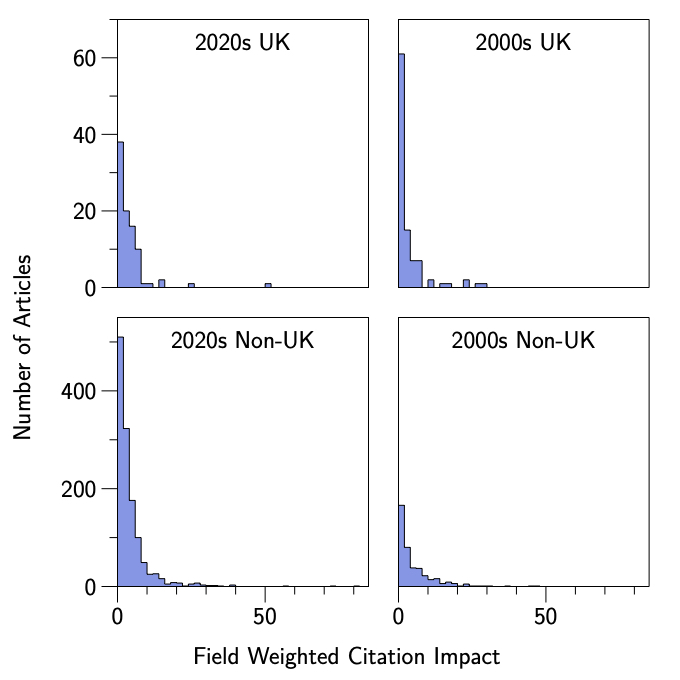
Conclusion
In sum, it seems that, in the case of mathematics education research, the published record is highly consistent with the hypothesis that UK-based academics tend to explicitly claim that their findings are original and significant in a manner that was not the case twenty years ago. This trend is significantly more pronounced among UK-based academics compared to academics based outside the UK. Of course, it is not possible to run experimental studies to investigate historical hypotheses, so strong claims about causality cannot be definitively made. But it does seem intuitively plausible to suggest that the REF, with its explicit definition of research quality as “originality, significance and rigour” is behind these trends.
Implications
Are these trends a problem? At least some journals regard it as inappropriate to emphasise claims of significance in academic manuscripts. For instance, the Journal of the Acoustical Society of America includes in its instructions to authors the stipulation that “No unsupported claims for novelty or significance should appear in the title or abstract, such as the use of the words new, original, novel, important, and significant.” In their analysis of scientific abstracts that appeared in PubMed between 1974 and 2014, Vinkers, Tijdink and Otte (2015) found an 880% increase in the number of positive words used (e.g. robust, novel, innovative). They expressed concern about this finding: “Although it is possible that researchers have adopted an increasingly optimistic writing approach and are ever more enthusiastic about their results, another explanation is more likely: scientists may assume that results and their implications have to be exaggerated and overstated in order to get published.” My analysis of mathematics education articles suggests an additional factor: perhaps UK authors assume that the significance of their work has to be exaggerated and overstated if they are to succeed in the REF?
References
Brown, R., & Carasso, H. (2013). Everything for sale? The marketisation of UK higher education. Routledge.
Edgington, E. S., & Onghena, P. (2007). Randomisation Tests (4th ed.). Chapman & Hall/CRC: New York.
Fairclough, N. (1995). Critical discourse analysis. Longman.
Gillies, D. (2008). How should research be organised? College Publications.
Inglis, M., Foster, C., Lortie-Forgues, H., & Stokoe, E. (in press). British education research and its quality: An analysis of Research Excellence Framework submissions. British Educational Research Journal.
Johnston, R. (2008). On structuring subjective judgements: Originality, significance and rigour in RAE2008. Higher Education Quarterly, 62(1‐2), 120-147.
Pardo-Guerra, J. P. (2022). The quantified scholar: How research evaluations transformed the British social sciences. Columbia University Press.
Vinkers, C. H., Tijdink, J. K., & Otte, W. M. (2015). Use of positive and negative words in scientific PubMed abstracts between 1974 and 2014: retrospective analysis. British Medical Journal, 351.
Weber, K., Inglis, M. & Mejia-Ramos, J. P. (2014). How mathematicians obtain conviction: Implications for mathematics instruction and research on epistemic cognition. Educational Psychologist, 49, 36-58.
Wheeler, B., & Torchiano, M. (2022). Package ‘lmperm’. R package version, 1-1.

Written By
Centre for Mathematical Cognition
Posted On
Centre for Mathematical Cognition
We write mostly about mathematics education, numerical cognition and general academic life. Our centre’s research is wide-ranging, so there is something for everyone: teachers, researchers and general interest. This blog is managed by Joanne Eaves and Chris Shore, researchers at the CMC, who edits and typesets all posts. Please email j.eaves@lboro.ac.uk if you have any feedback or if you would like information about being a guest contributor. We hope you enjoy our blog!


Centre for Mathematical Cognition
We write mostly about mathematics education, numerical cognition and general academic life. Our centre’s research is wide-ranging, so there is something for everyone: teachers, researchers and general interest. This blog is managed by Joanne Eaves and Chris Shore, researchers at the CMC, who edits and typesets all posts. Please email j.eaves@lboro.ac.uk if you have any feedback or if you would like information about being a guest contributor. We hope you enjoy our blog!