At the University we often have visitors come to our departments. These might be visiting students, visiting academics, contractors visiting to work for the University and all manner of other types of non-member visitor to our campus.
We also have partner organisations that are based on the campus, including sports governing bodies and commercial tenants. The commercial tenants rent space on site for their company and many are spin outs from academic departments or new start ups being run by students or recent graduates.
All of these individuals may need to be issued with identity cards and/or IT access in various forms. A few years ago we were tasked with replacing an existing commercial system to manage them as part of a larger identity management project. The basic requirements were to allow new visitor or tenant users to be requested, have a workflow for checking the requests, managing the ID numbers they are allocated and then tracking the subsequent life cycle of the individual and the organisation of which they are a part. Visitor users and tenant users are slightly different – visitors are requested by a member of University staff who acts as their “guarantor” and they can be either “staff-like” or “student-like”. Visitor accounts can be requested for up to a year, with yearly renewals after that. Tenants on the other hand are requested by the organisation they are a part of and can be valid for as long as the organisation they are part of is a valid tenant on the campus.
Now our team looks after the Request Tracker (RT) system for the University, and we had the bright idea that maybe RT could manage these identities? After all, RT tracks the workflow of a work ticket from creation, through various states until it is rejected or resolved. What we were looking at with visitors and tenants was a workflow, so maybe an RT ticket could represent each individual in the system? These individuals would each be in a single organisation, so in RT terms this is like having a ticket in a queue. So the RT queues could represent the different organisational units of the University and partner/tenant organisations. But would this work?
The answer is (possibly unsurprisingly) yes. We call the resulting system “ALMS”: the Account Lifecycle Management System. ALMS uses RT as a base with lots of custom code, workflows and interactions with other systems. It is highly tied to the way we work at Loughborough University, but the general idea might be applicable elsewhere, hence this posting.
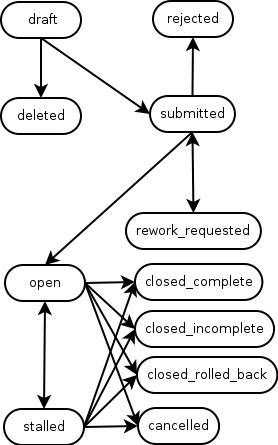
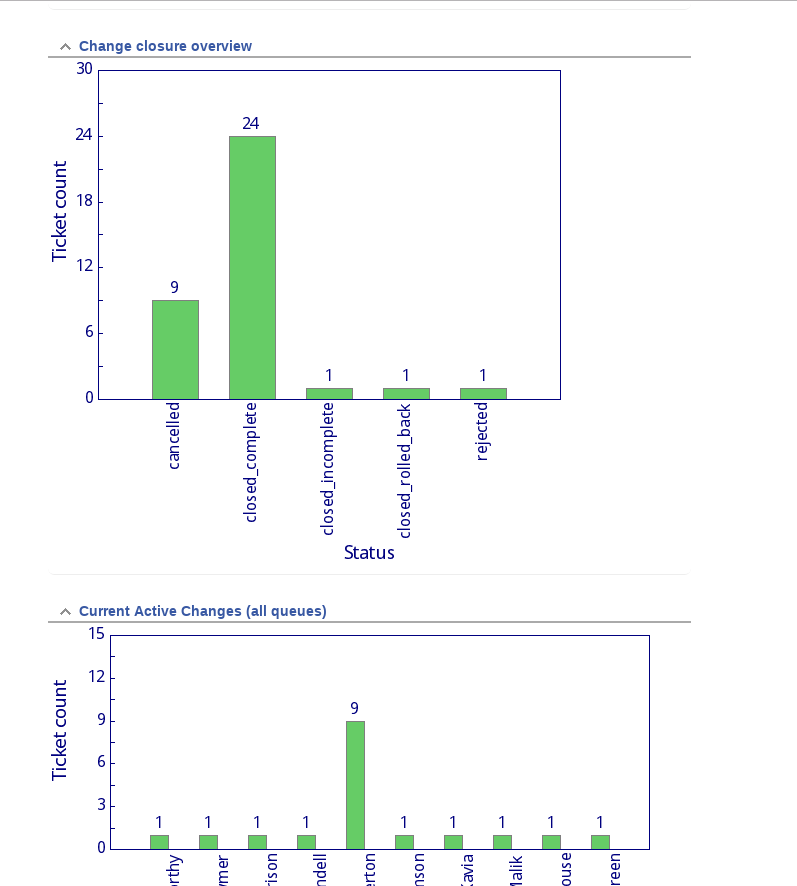
We start with custom RT lifecycles for each of Visitors and Tenants. As normal these detail the various states that a ticket (in our case an individual) can be in as their pass through our visitor/tenant identity management process.
Queues were set up for both University schools/departments/sections and partner organisations, with custom fields attached to each queue to give us some “metadata” about the organisation. For example the dates when the organisation is valid from and to, whether it is part of the University or a tenant organisation on campus, contact details for tenant organisation management, etc.
Within these queues we could create tickets, one per individual visitor or tenant person. These tickets also have a range of custom fields attached to them that allow us to capture things like their given name, last name, contact email/phone details, whether they need a building access ID card issuing, what sort of IT access (if any) they require, when they should be valid from and to, etc. One custom field holds a University ID number that is issued to them as they run through the workflow and is used later by ID card systems and/or for the creation of Active Directory accounts.
We also implemented an approvals process, not using RT’s built in approvals but by using ticket statuses and a set of custom user interfaces written in the Mason framework that underpins RT. We felt that gave us greater flexibility, was more transparent and easier for the users to understand. Ticket status changes are constrained by both the lifecycle transitions defined in the RT site config files, and which groups in RT can access these user interfaces. We have groups for our campus card desk, the IT service desk, University departmental management approvers and various administrative groups.
For visitors, there is an ALMS self service form that any member of University staff can use to start a request. We ask them for the visitors basic details such as given and last names, what department they are visiting, why they are visiting (from a selected list of potential reasons), whether an ID card and/or IT access is required, how long (up to a year) the visitor will be required for, etc. Once all the required information is captured and submitted, a new RT tickets is created in the correct department’s queue.
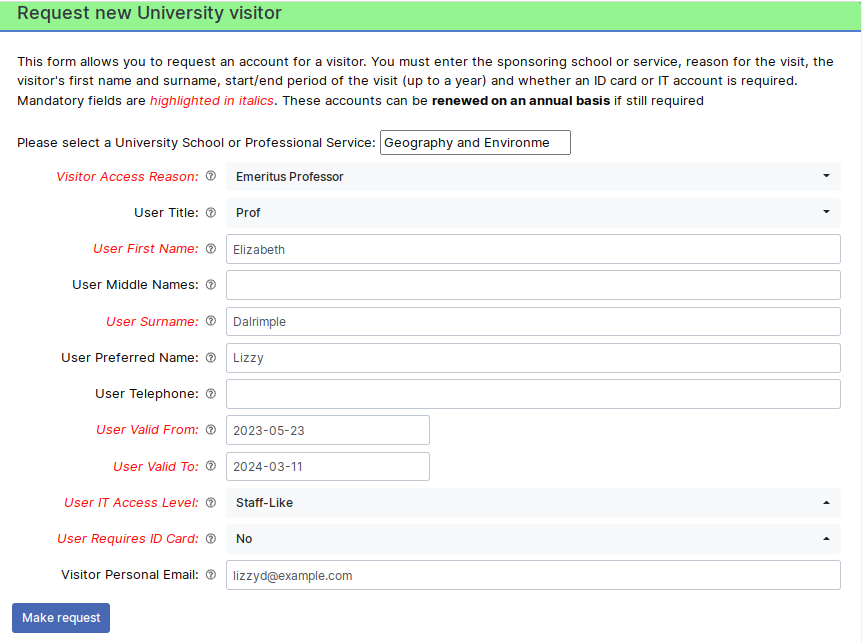
The first port of call is then the department’s management approver(s). These are usually senior managers or administrative staff in the department who can vet the suitability of the request for this visitor. Assuming they approve it, the IT service desk and campus card desk groups are then asked for their approval. Which of them are involved depends on the requirements for ID cards and IT access obviously – no point involving the card desk in an approval for a visitor that does not require an ID card for example. If IT access is requested, custom code picks the required details from the RT ticket once IT service desk approval is given and “mints” a username and/or email address using another system we have on site.
Assuming these groups also approve the visitor, the ticket enters a “Pending” status. It is waiting for its “valid from” custom field date to be reached, at which point the status will be changed to “Active”. This change is done by a regularly run rt-crontool job. Another rt-crontool job does a similar job but looks for when the “valid to” date is approaching and sets the status to “Expiring”. This is a cue for scrips to send out reminders messages to the visitor and their requesting University guarantor that their record will soon expire and will need renewal if they are to maintain the access they have. The guarantor staff member can use another self server custom user interface to submit this renewal request. If the visitor is not renewed by their valid to date, the ticket status is changed by yet another cron job to be “Disabled”.
Tickets in “Active”, “Expiring” and “Disabled” statuses are regularly picked up by our main identity management system using the RT REST2 API. This system is designed to be more generic than just handling visitors and tenants, and gathers user information from not only ALMS but also other identity source systems such as our main student and HR management systems. It is this system that actually does the dirty work of creating and updating records in the Active Directory and passing information required by the building access system for ID card manufacture.
A similar process exists for the tenant users, but in this case there is no self-service request aspect as the tenant organisations request new individuals directly to the campus card desk. When a tenant staff member leaves the organisation it is up to that organisation’s management to tell the University so that we can update the valid to date in the user ticket (which will then start the expiry/disabled status process, but without any emails to guarantors for renewal as there is with visitors).
ALMS also provides some reporting information to IT, campus card desk and our commercial partner management groups. It is easy to use RT’s reporting system to provide er organisation lists of users, with break downs by Pending, Active, Expiring or Disabled status for example.
Whilst this has taken some local development work the result seems to be working OK. It has been in service for nearly a year now, and is managing several thousand visitors and tenants. The great thing about using open source software such as RT as the basis of this system is that it has not only cut down our development time considerably but it is far easier for us to customise than some of the commercial systems targeted directly at this market. That makes it cost effective, even factoring our local development and maintenance effort.