Loughborough Online Reading List System
Posts tagged LORLS v7
Purchasing Prediction
25 Mar 2013
by Jon Knight
in LORLS
For a while now we’ve been feverishly coding away at the top secret LORLS bunker on a new library management tool attached to LORLS: a system to help predict which books a library should buy and roughly how many will be required. The idea behind this was that library staff at Loughborough were spending a lot of time trying to work out what books needed to be bought, mostly based on trawling through lots of data from systems such as the LORLS reading list management system and the main Library Management System (Aleph in our case). We realised that all of this work was suitable for “mechanization” and we could extract some rules from the librarians about how to select works for purchase and then do a lot of the drudgery for them.
We wrote the initial hack-it-up-and-see-if-the-idea-works-at-all prototype about a year ago. It was pretty successful and was used in Summer 2012 to help the librarians decide how to spend a bulk book purchasing budget windfall from the University. We wrote up our experiences with this code as a Dlib article which was published recently. That article explains the process behind the system, so if you’re interested in the basis behind this idea its probably worth a quick read (or to put it in other terms, I’m too lazy to repeat it here! 😉 ).
Since then we’ve stepped back from the initial proof of concept code and spent some time re-writing it to be more maintainable and extensible. The original hacked together prototype was just a single monolithic Perl script that evolved and grew as we tried ideas out and added features. It has to call out to external systems to find loan information and book pricing estimates with bodges stuffed on top of bodges. We always intended it to be the “one we threw away” and after the summer tests it became clear that the purchase prediction could be useful to the Library staff and it was time to do version 2. And do it properly this time round.
The new version is modular… using good old Perl modules! Hoorah! But we’ve been a bit sneaky: we’ve a single Perl module that encompasses the purchase prediction process but doesn’t actually do any of it. This is effectively a “wrapper” module that a script can call and which knows about what other purchase prediction modules are available and what order to run them in. The calling script just sets up the environment (parsing CGI parameters, command line options, hardcoded values or whatever is required), instantiates a new PurchasePrediction object and repeatedly calls that object’s DoNextStep() method with a set of input state (options, etc) until the object returns an untrue state. At that point the prediction has been made and suggestions have, hopefully, been output. Each call to DoNextStep() runs the next Perl module in the purchase prediction workflow.
The PurchasePrediction object comes with sane default state stored within it that provides standard workflow for the process and some handy information that we use regularly (for example ratios of books to students in different departments and with different levels of academic recommendation in LORLS. You tend to want more essential books than you do optional ones obviously, whilst English students may require use of individual copies longer than Engineering students do). This data isn’t private to the PurchasePredictor module though – the calling script could if it wished alter any of it (maybe change the ratio of essential books per student for the Physics department or even alter the workflow of the purchase prediction process).
The workflow that we currently follow by default is:
- Acquire ISBNs to investigate,
- Validate those ISBNs,
- Make an initial estimate of the number of copies required for each work we have an ISBN for,
- Find the cost associated with buying a copy of each work,
- Find the loan history of each work,
- Actually do the purchasing algorithm itself,
- Output the purchasing suggestions in some form.
Each of those steps is broken down into one or more (mostly more!) separate operations, with each operation then having its own Perl module to instantiate it. For example to acquire ISBNs we’ve a number of options:
- Have an explicit list of ISBNs given to us,
- Find the ISBNs of works on a set of reading list modules,
- Find the ISBNs of works on reading lists run by a particular department (and optionally stage within that department – ie First Year Mech Eng)
- Find ISBNs from reading list works that have been edited within a set number of days,
- Find all the ISBNs of books in the entire reading list database
- Find ISBNs of works related to works that we already have ISBNs for (eg using LibraryThing’s FRBR code to find alternate editions, etc).
Which of these will do anything depends on the input state passed into the PurchasePredictor’s DoNextStep() method by the calling script – they all get called but some will just return the state unchanged whilst others will add new works to be looked at later by subsequent Perl modules.
Now this might all sound horribly confusing at first but it has big advantages for development and maintenance. When we have a new idea for something to add to the workflow we can generate a new module for it, slip it into the list in the PurchasePredictor module’s data structure (either by altering this on the fly in a test script or, once the new code is debugged, altering the default workflow data held in the PurchasePredictor module code) and then pass some input to the PurchasePredictor module’s DoNextStep() method that includes flags to trigger this new workflow.
For example until today the workflow shown in the second list above did not include the step “Find ISBNs from reading list works that have been edited within a set number of days”; that got added as a new module written from scratch to a working state in a little over two hours. And here’s the result, rendered as an HTML table:
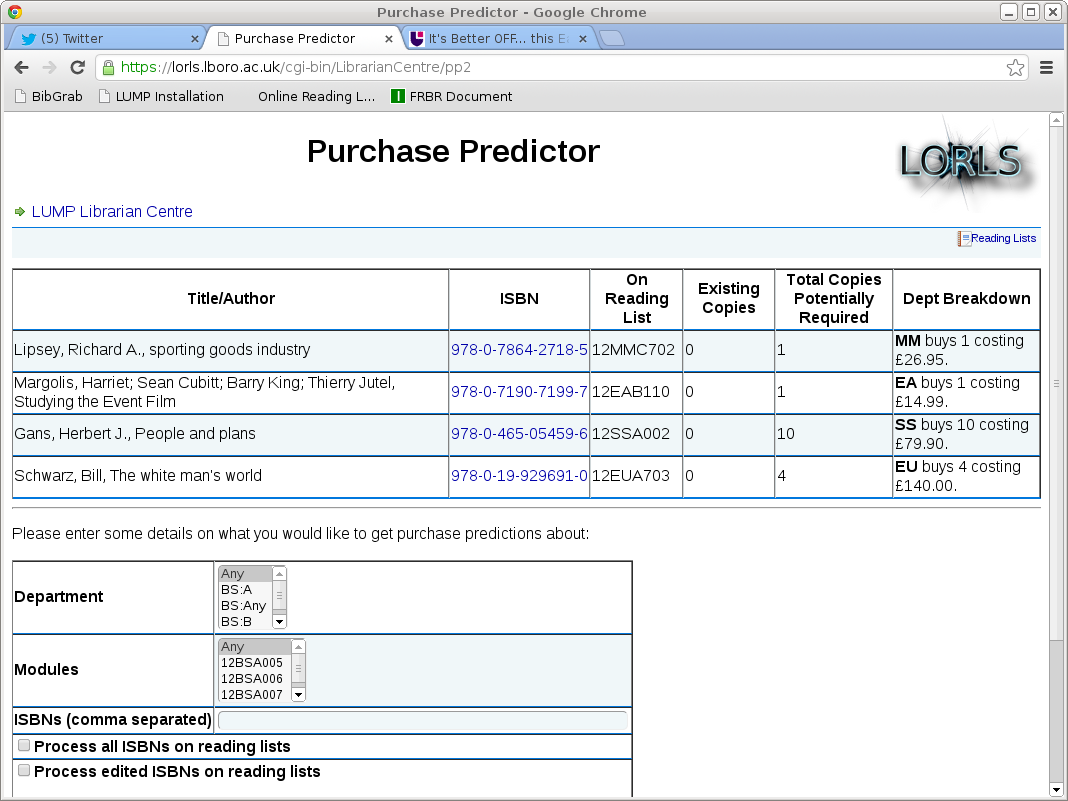
Purchase Predictor pp2 HTML showing suggested purchases for works in LORLS edited in the last day.
As you can see the purchase predictor HTML output in this case tries to fit in with Jason’s new user interface, which it can do easily as that’s all encompassed in Perl modules as well!
There’s still lots more work we’ve can do with purchase prediction. As one example, the next thing on my ‘To Do’ list is to make an output module that generates emails for librarians so that it can be run as batch job by cron every night. The librarians can then sip their early morning coffee whilst pondering which book purchasing suggestions to follow up. The extensible modular scheme also means we’re free to plug in different actual purchasing algorthims… maybe even incorporating some machine learning, with feedback provided by the actual purchases approved by the librarians against the original suggestions that the system made.
I knew those undergraduate CompSci Artificial Intelligence lectures would come in handy eventually… 🙂
LORLS v7 now available
26 Nov 2012
by Gary Brewerton
in LORLS
With great pleasure (trumpet fanfare not included) I can now announce the release of LORLS version 7. Key features include:
|
 |
LORLS v7 is available for download from this website.