LORLS
Loughborough Online Reading List System
Recently we have looked at improving some of the tables in CLUMP. At first we thought that it would involve quite a bit of work, but then we came across the DataTables jQuery plugin. After a couple of days of coding we’ve used it to enhance a number of tables on our development version of CLUMP. Key features that attracted us to it are:
DataTables is made available under an MIT Licence, so it is very developer friendly.
As one of the many data sources that DataTables supports is the DOM you can use it to quickly enhance an existing table.
Sometimes a long table can be unwieldy, with the pagination options in DataTables you can specify how many entries to show by default and how the next/previous page options should be presented to the user. Of Course you can disable the pagination to display the data in one full table.
One of the most useful features DataTables has is its ability to allow the user to order the table by any column by simply clicking on that column’s header, an action that has become second nature to a lot of users. It’s also possible to provide custom sorting functions for columns if the standard sorting options don’t work for the data they contain.
As users type their search terms into the search box DataTables hides table rows that don’t meet the current search criteria.
There are a number of extensions available for DataTables that enhance its features, from allowing users to reorder the column by dragging their headers about, to adding the option for users to export the table to the clipboard or exporting it as a CSV, XLS or even a PDF.
If you have some bespoke functionality required then you can use its plug-in Architecture to create your own plugin to meet it.
We’ve been thinking recently about how to make it easier for people to try out the LORLS code. This includes ourselves – we sometimes want to spin up a new instance of LORLS for testing some feature or helping another site debug their installation. Normally that would mean doing an operating system, Perl module and then LORLS installation on a new machine (physical or virtual) before it could be used.
With the spread of virtual machine (VM) infrastructure, and the fact that many Universities now use VMs widely, we thought it might be worth making a “LORLS in a box” VM appliance image that people could grab and then use for testing, demos or as the basis of their own installation. The VM image would have LORLS pre-installed along with all the basic Perl modules required in place, and the test data that we use in our local sandbox instance.
To that end, here’s a first cut of a LORLS in a box VM image. This is an OVA virtual machine image (both the VM and the disc image). Be warned that its quite large (over 900MB!) as it has a full operating system disc image included – you might want to have a cup of tea and biscuit handy whilst it downloads. The image was built using the Virtual Box OSE VM platform and is based on a CentOS 6 Linux base, and it should be able to be imported into other VM infrastructures such as VMware.
Once you’ve imported the LORLs-in-a-box VM into your VM infrastructure and started it up, you’ll eventually be presented with a login on the console. Your VM system may complain about not having a matching ethernet controller the first time you run the VM image – you can ignore this error as the LORLS VM image should work round it when it boots up. Once booted, the console should also show you the IP address that the VM has picked up and the URL that you can use to get to the CLUMP web front end. By default the networking in the VM is using a bridged interface that picks up an IPv4 address via DHCP. This is fine for testing and development, though if you’re using this image as the basis of a production system you’ll probably want to nip in and change this to a static IP address.
To login to the system there’s a “lorls” user with the password “lorls4you” (both without the quotes). This user can then act as the superuser by using sudo. The MySQL server on the machine has a root user password of “LUMPyStuff!” (again quoteless) should you wish to go in and tinker with the database directly. You probably want to change all these passwords (and Linux root password) as soon as you can as everyone now knows them! You’ll also most probably want to edit /usr/local/LUMP/LUMP.pm file to point at your own site’s Z39.50 server, etc. There are a couple of demo LORLS web users hard coded into this demo system – user aker (password “demic”) is an academic that owns a reading list, and user “libby” (password “rarian”) is a library staff user.
We’ve been looking at intergrating the Koha LMS with the LORLS reading list management system, as we know of sites using Koha that are interested in LORLS (and also because we’re interested in seeing how Koha works!). After getting the basic integration for looking up works using Koha’s Z39.50 server and finding out item holdings/availability working last week, the next thing to tackle was to get loan histories out of Koha.
We use loan histories in LORLS’s purchase predictor code. We need to be able to grab an XML feed of both current and old loan issues, which is then used to work out what the peak number of concurrent loans have been made for an item and thus whether it has had sufficient demand to warrant purchasing additional copies.
For the current loans we need to know the date and time they were issued and for old issues we want both the issue date/time and the return date/time. For both current and old loan issues we also want to know the type (status) of the item (“long_loan”, “short_loan”, etc) and which department the borrower of the loan came from. The latter is so that we can apportion purchasing costs between different departments for the cases where multiple modules include the same books on their reading lists.
The item status is fairly easy to do in Koha – we’d already created item types in Koha and these can easily be mapped in the Perl code that implements the XML API into the long_loan, short_loan, week_loan, etc status format our purchase predictor code already expects. Indeed if we wanted to we could make the items types in Koha just be “long_loan”, “short_loan” and “week_loan” so no mapping would be required, but a mapping function adds a bit of flexibility.
The borrowers’ department is a bit more involved. It appears that in Koha this would be an “extended attribute” which needs to be enabled (it doesn’t appear to be on by default). I created an extended borrower attribute type of called DEPT, and then entered some of Loughborough’s department codes as a controlled vocabulary for it. In real life these would have to be slipped into Koha as part of a regularly (probably daily) borrower upload from our central reservation systems, which is roughly how we do it with our production Aleph LMS. In our test environment I just added the extended attribute value manual to a couple of test users so that we could play with the code.
At the end of this posting you’ll find the resulting Perl code for creating this simple XML feed, which Koha sites might find handy even if they don’t use LORLS. One interesting thing to note in Koha is that the isbn field of the biblioitems table appears to contain more than one ISBN, separated by white space and vertical bar character (” | “). This means that you need to do a “like” match on the ISBN. This was a little unexpected and took me a while to track down what was wrong with my SQL when I had a simple “=” rather than a “like” in the select statements! The separation of biolios (works), biblioitems (manifestations) and items (er, items) is nicely done though.
#!/usr/bin/perl
use strict;
use lib '/usr/share/koha/lib';
use CGI;
use DBI;
use C4::Context;
$| = 1;
my $q = new CGI;
my $isbn = $q->param('isbn');
my $dept_code = $q->param('dept_code');
my $return_period = $q->param('return_period') || 365;
print STDOUT "Content-type: text/xmlnn";
print STDOUT "<loan_history>n";
my $status_map = {
'BK' => 'long_loan',
'SL BOOK' => 'short loan',
'WL BOOK' => 'week loan',
'REFBOOK' => 'reference',
};
my $dbh = C4::Context->dbh;
my $total_number = 0;
my $sql =
'select items.itemnumber, issues.issuedate, biblioitems.itemtype, ' .
' borrower_attributes.attribute ' .
'from biblioitems, items, issues, borrowers, borrower_attributes, ' .
' borrower_attribute_types ' .
'where biblioitems.isbn like ' . $dbh->quote("%$isbn%") . ' and ' .
' biblioitems.biblioitemnumber = items.biblioitemnumber and ' .
' items.itemnumber = issues.itemnumber and ' .
' issues.borrowernumber = borrowers.borrowernumber and ' .
' borrowers.borrowernumber = borrower_attributes.borrowernumber and '.
' borrower_attributes.code = borrower_attribute_types.code and ' .
' borrower_attribute_types.description = "Department" and ' .
' borrower_attributes.attribute = ' . $dbh->quote($dept_code);
my $currentloan = $dbh->prepare($sql);
$currentloan->execute;
while (my ($id, $issuedate, $status, $bor_type) = $currentloan->fetchrow_array) {
$status = $status_map->{$status};
print STDOUT " <loan>n";
print STDOUT " <issue_date>$issuedate</issue_date>n";
print STDOUT " <status>$status</status>n";
print STDOUT " <dept_code>$bor_type</dept_code>n";
print STDOUT " <number>1</number>n";
print STDOUT " <current>Y<current>n";
print STDOUT " </loan>n";
$total_number++;
}
$currentloan->finish;
my($sec,$min,$hour,$mday,$mon,$year,$wday,$yday) = gmtime(time-($return_period * 24 * 60 * 60));
$year += 1900;
$mon++;
my $target_date = sprintf("%04d%02d%02d",$year,$mon,$mday);
$sql =
'select items.itemnumber, old_issues.issuedate, old_issues.returndate, ' .
' biblioitems.itemtype, borrower_attributes.attribute ' .
'from biblioitems, items, old_issues, borrowers, borrower_attributes, ' .
' borrower_attribute_types ' .
'where biblioitems.isbn like ' . $dbh->quote("%$isbn%") . ' and ' .
' biblioitems.biblioitemnumber = items.biblioitemnumber and ' .
' items.itemnumber = old_issues.itemnumber and ' .
' old_issues.returndate > ' . $dbh->quote($target_date) . ' and ' .
' old_issues.borrowernumber = borrowers.borrowernumber and ' .
' borrowers.borrowernumber = borrower_attributes.borrowernumber and '.
' borrower_attributes.code = borrower_attribute_types.code and ' .
' borrower_attribute_types.description = "Department" and ' .
' borrower_attributes.attribute = ' . $dbh->quote($dept_code);
my $pastloan = $dbh->prepare($sql);
$pastloan->execute;
while (my ($id, $issuedate, $return_date, $status, $bor_type) = $pastloan->fetchrow_array)
{
$status = $status_map->{$status};
print STDOUT " <loan>n";
print STDOUT " <issue_date>$issuedate</issue_date>n";
print STDOUT " <return_date>$returndate</return_date>n";
print STDOUT " <status>$status</status>n";
print STDOUT " <dept_code>$bor_type</dept_code>n";
print STDOUT " <number>1</number>n";
print STDOUT " <current>N<current>n";
print STDOUT " </loan>n";
$total_number++;
}
$pastloan->finish;
print STDOUT " <total_loan_count>$total_number</total_loan_count>n";
print STDOUT "</loan_history>n";
At Loughborough we use Ex Libris’s Aleph as our Library Management System (LMS). Our LORLS reading list system also makes use of Aleph in a number of ways:
We’ve recently had another site say they are interested in using LORLS, but they use the Koha LMS. They asked us what would be needed to allow LORLS to integrate with Koha? Luckily Koha is open source, so we could just download a copy and install it on a new virtual machine to have a play with and see what was needed.
Looking up bibliographic information was pretty simple to support. Koha has a built in Z39.50 server, so all we needed to do was to tweak the LUMP.pm file on our dev server to point the Z3950Hostname(), Z3950Port() and Z3950DBName() to point to our new VM, the port that Koha’s Z39.50 server is running on and the new Z39.50 database name (which appears to default to “biblios”). That seemed to work a treat.
Get item holdings for works was a bit more involved. Koha obviously doesn’t have Ex Libris’s X server, so we needed another way to get similar data. Luckily Koha does implement some of the Digital Library Federation Integrated Library System – Discovery Interface recommendations. One of these Application Programming Interfaces (APIs) is called GetRecords() and, given a set of system record identifiers, will return an XML document with just the sort of information we need (eg for each item linked to a work we get things like item type, whether it can be loaned, what its due date is if it is on loan, if it is damaged, lost, etc).
Unfortunately LORLS doesn’t know anything about Koha’s system record identifiers, and the GetRecords() ILS-DI API doesn’t appear to allow searches based on control numbers such as ISBNs. To get the system record numbers we can however fall back on Z39.50 again, which Koha uses to implement the ILS-DI SRU type interfaces. Searching for a Bib-1 attribute of type 1007 with the value set to be the ISBN gets us some nice USMARC records to parse. We need to look at the 999 $c field in the MARC record as this appears to be the Koha system record identifier.
Just to make things interesting we discovered accidentally that in Koha you can end up with more than one work for the same ISBN (and each work can then have multiple physical items). I guess this is a flexibility feature in some way, but it means that we need to make sure that we get all the system record identifiers that match our ISBN from LORLS and then pass all of these to the Koha GetRecords() API. Luckily the API call can take a whole set of system record identifiers in one go, so this isn’t too much of a problem.
One thing we do have to have in the code though is some way of distinguishing between loan categories (long loan, short loan, week loan, reference, etc). In Koha you can create an arbitrary number of item types which can correspond to loan categories, to which you can then assign things like differing loan rules. We slipped in:
Our code currently then has these hard coded in order to return the same sort of holdings Perl structure that Aleph did. Extra item types assigned in Koha will need to been inserted into this code – we might have to think of a “nice” way of doing this if folk make lots of these changes on a regular basis but I suspect item types are one of those things that are configured when an LMS is setup and rarely, if ever, tweaked again.
In the StructuralUnit.pm Perl module I created a new method called Koha_ILS_DI_Holdings() to implement the new Koha item holdings and availability code. The existing Holdings() method was renamed to Aleph_Holdings() and a new Holdings() method implemented that checks a new Holdings() method in LUMP.pm for the name of a holdings retrieval algorithm to use (currently now either “Koha:ILS-DI” which selects the new code, or anything else defaulting back to the old Aleph_Holdings() method). This means that if someone else comes along with XYZ Corp LMS that uses some other whacky way of retrieving holdings availability we can simply write a new method in StructuralUnit.pm and add another if clause to the Holdings() method to allow a quick LUMP.pm change to select it. The advantage of this is that other code in LORLS that uses the Holdings() method from StructuralUnit.pm doesn’t have to be touched – it is insulated from the messy details of which implementation is in use (ooh, object oriented programming at work!).
This appears to work on our test set up and it means we can just ship a new StructuralUnit.pm and LUMP.pm file to the folk with Koha and see how they get on with it. Our next trick will be getting loan history information out of Koha – this may take a bit more work and its really replacing functionality that we’ve mostly implemented solely for Loughborough (using our custom scripts as even Aleph didn’t provide a usable API for what we needed). It doesn’t appear at first glance that Koha’s ILS-DI APIs cover this use case – I guess we’re a bit odd in being interested in work loan histories!
When we think of reading lists we often try to look at it from the point of view of one or more of our user communities. We’ve got academics who want to have a quick and easy way to add and remove material from lists that they can then use to guide their students’ learning. We’ve got the students themselves who want pointers to works that they’ll need for reports and projects, preferably with as many online resources as possible. And we’ve got the librarians who need to use reading lists to help manage the book stocks and ensure that library budgets are spent wisely.
However today I’ve been hacking on some code for a different user community: prospective students. There’s actually really two camps here as well: people who are thinking about applying for a course at the University and those that have already applied and are waiting to be accepted and join their course in the next academic year. In either camp though there are individuals who would like to get guidance on the sort of material they will be expected to read when they come to the University to study. Our librarians already get the occasional request come in along these lines so we know there is a latent interest in this. And this is where the reading list data base can come in….
The LORLS database at Loughborough holds quite a lot of data on module reading lists., with a pretty high coverage rate of modules across all the schools and departments on campus. As part of academics providing information about each work on their list we’ve asked them to, where possible, make judgements as to the level of recommendation each work has. For example they may say that one book is absolutely essential, another comes highly recommended if you can get it and a third is OK as an optional reading source to provide a fuller understanding of a topic. Obviously only the really core texts for a module are marked as essential, even on really large reading lists.
My new program makes use of these academic supplied recommendations to find out what books are judged as essential on foundation and first year undergraduate modules within a department. Whilst not all of these modules in all departments will be compulsory for all students, they do give a good idea of what the core reading is likely to be for students in their initial year on campus. Indeed having a list of essential works to flick through in a local library or bookshop (or via extracts on Google Books!) before they turn up may help some prospective students make quicker decisions about any module options they are offered.
The code is pretty Loughborough centric so it isn’t likely to appear in the LORLS distributions directly: it has to wander over to our central information systems front end to get a list of modules for a department’s first year (as some departments may share modules on joint honours courses). In the future we might want to get more granularity by allowing prospective students to specify not only the department they are interested in but the programme of study itself (by name and/or UCAS code for example). However we get the list of modules though, the next step is purely based on running through the LORLS database to find the works that have essential recommendation levels at the moment.
Of course that list of works might be extended if this is actually implemented as a production service. For example if a department doesn’t have any works in any foundation or first year module marked as “essential” (some don’t!), we might want the code to fall back to looking at recommended works that are heavily borrowed (so linking in with our Aleph LMS’s borrower history as we’ve done in the past for our high demand reports and purchase prediction code). Or the University might want to add some non-academic pastoral support texts to the list (time and money management techniques, study skills, etc). Lots of options to consider there.
Once we’ve got the list of books that can be used as suggestions to the prospective students, we have some more options in how to present them. At the moment the code implements two options. The first of these is to display a simple HTML page containing the citations. Each work’s ISBN is hyperlinked to Google Books so that the prospective student (or their friends and family) can see cover art, read some extracts and potentially buy a copy online.
At the bottom of this list we also provide the second option: a link to allow the student to add the works found to a new virtual bookshelf on Goodreads.com. From there they can look at reviews, rankings, share with their friends, and do all the other social reading things that Goodreads permits. We called the new shelf “loughborough-wishlist” as it may well be the books they’d like to buy (or have others buy for them!).
This second option is a specific implementation of something we’ve been thinking about more generally for a while: getting our LORLS data linked in with various third party social media and sharing services that the users are already using. We picked Goodreads.com because the API is clean and provides exactly what we need. We’d like to do it with other services such as LibraryThing.com, Google Books, Amazon wishlists or even Facebook (which does have a Books API surprisingly).
We are now waiting for our library colleagues to evaluate the results before we consider going live with this system. We’ll probably want to pass it by the academic departments before it gets sent out to prospective students so that they have a chance to check what, if any, recommendations have been made for readings during the first year that will show up to prospective students.
However, what this program does demonstrate though is that once we have a suitably large body of data in a library system we can start to look at it in new ways and help new user communities. In this case the more that can be done to help engage prospective students and ease their transition into being a student, the better the chance that they’ll make the right choice and pick Loughborough as the place for their academic career.
Part of my day job is developing and gluing together library systems. This week I’ve been making a start on doing some of this “gluing” by prototyping some code that will hopefully link our LORLS reading list management system with the Goodreads social book reading site. Now most of our LORLS code is written in either Perl or JavaScript; I tend to write the back end Perl stuff that talks to our databases and my partner in crime Jason Cooper writes the delightful, user friendly front ends in JavaScript. This means that I needed to get a way for a Perl CGI script to take some ISBNs and then use them to populate a shelf in Goodreads. The first prototype doesn’t have to look pretty – indeed my code may well end up being a LORLS API call that does the heavy lifting for some nice pretty JavaScript that Jason is far better at producing than I am!
Luckily, Goodreads has a really well thought out API, so I lunged straight in. They use OAuth 1.0 to authenticate requests to some of the API calls (mostly the ones concerned with updating data, which is exactly what I was up to) so I started looking for a Perl OAuth 1.0 module on CPAN. There’s some choice out there! OAuth 1.0 has been round the block for a while so it appears that multiple authors have had a go at making supporting libraries with varying amounts of success and complexity.
So in the spirit of being super helpful, I thought I’d share with you the prototype code that I knocked up today. Its far, far, far from production ready and there’s probably loads of security holes that you’ll need to plug. However it does demonstrate how to do OAuth 1.0 using the Net::OAuth::Simple Perl module and how to do both GET and POST style (view and update) Goodreads API calls. Its also a great way for me to remember what the heck I did when I next need to use OAuth calls!
First off we have a new Perl module I called Goodreads.pm. Its a super class of the Net::OAuth::Simple module that sets things up to talk to Goodreads and provides a few convenience functions. Its obviously massively stolen from the example in the Net::OAuth::Simple perldoc that comes with the module.
#!/usr/bin/perl
package Goodreads;
use strict;
use base qw(Net::OAuth::Simple);
sub new {
my $class = shift;
my %tokens = @_;
return $class->SUPER::new( tokens => %tokens,
protocol_version => '1.0',
return_undef_on_error => 1,
urls => {
authorization_url => 'http://www.goodreads.com/oauth/authorize',
request_token_url => 'http://www.goodreads.com/oauth/request_token',
access_token_url => 'http://www.goodreads.com/oauth/access_token',
});
}
sub view_restricted_resource {
my $self = shift;
my $url = shift;
return $self->make_restricted_request($url, 'GET');
}
sub update_restricted_resource {
my $self = shift;
my $url = shift;
my %extra_params = @_;
return $self->make_restricted_request($url, 'POST', %extra_params);
}
sub make_restricted_request {
my $self = shift;
croak $Net::OAuth::Simple::UNAUTHORIZED unless $self->authorized;
my( $url, $method, %extras ) = @_;
my $uri = URI->new( $url );
my %query = $uri->query_form;
$uri->query_form( {} );
$method = lc $method;
my $content_body = delete $extras{ContentBody};
my $content_type = delete $extras{ContentType};
my $request = Net::OAuth::ProtectedResourceRequest->new(
consumer_key => $self->consumer_key,
consumer_secret => $self->consumer_secret,
request_url => $uri,
request_method => uc( $method ),
signature_method => $self->signature_method,
protocol_version => $self->oauth_1_0a ?
Net::OAuth::PROTOCOL_VERSION_1_0A :
Net::OAuth::PROTOCOL_VERSION_1_0,
timestamp => time,
nonce => $self->_nonce,
token => $self->access_token,
token_secret => $self->access_token_secret,
extra_params => { %query, %extras },
);
$request->sign;
die "COULDN'T VERIFY! Check OAuth parameters.n"
unless $request->verify;
my $request_url = URI->new( $url );
my $req = HTTP::Request->new(uc($method) => $request_url);
$req->header('Authorization' => $request->to_authorization_header);
if ($content_body) {
$req->content_type($content_type);
$req->content_length(length $content_body);
$req->content($content_body);
}
my $response = $self->{browser}->request($req);
return $response;
}
1;
Next we have the actual CGI script that makes use of this module. This shows how to call the Goodreads.pm (and thus Net::OAuth::Simple) and then do the Goodreads API calls:
#!/usr/bin/perl
use strict;
use CGI;
use CGI::Cookie;
use Goodreads;
use XML::Mini::Document;
use Data::Dumper;
my %tokens;
$tokens{'consumer_key'} = 'YOUR_CONSUMER_KEY_GOES_IN_HERE';
$tokens{'consumer_secret'} = 'YOUR_CONSUMER_SECRET_GOES_IN_HERE';
my $q = new CGI;
my %cookies = fetch CGI::Cookie;
if($cookies{'at'}) {
$tokens{'access_token'} = $cookies{'at'}->value;
}
if($cookies{'ats'}) {
$tokens{'access_token_secret'} = $cookies{'ats'}->value;
}
if($q->param('isbns')) {
$cookies{'isbns'} = $q->param('isbns');
}
my $oauth_token = undef;
if($q->param('authorize') == 1 && $q->param('oauth_token')) {
$oauth_token = $q->param('oauth_token');
} elsif(defined $q->param('authorize') && !$q->param('authorize')) {
print $q->header,
$q->start_html,
$q->h1('Not authorized to use Goodreads'),
$q->p('This user does not allow us to use Goodreads');
$q->end_html;
exit;
}
my $app = Goodreads->new(%tokens);
unless ($app->consumer_key && $app->consumer_secret) {
die "You must go get a consumer key and secret from Appn";
}
if ($oauth_token) {
if(!$app->authorized) {
GetOAuthAccessTokens();
}
StartInjection();
} else {
my $url = $app->get_authorization_url(callback => 'https://example.com/cgi-bin/good-reads/inject');
my @cookies;
foreach my $name (qw(request_token request_token_secret)) {
my $cookie = $q->cookie(-name => $name, -value => $app->$name);
push @cookies, $cookie;
}
push @cookies, $q->cookie(-name => 'isbns',
-value => $cookies{'isbns'} || '');
print $q->header(-cookie => @cookies,
-status=>'302 Moved',
-location=>$url,
);
}
exit;
sub GetOAuthAccessTokens {
foreach my $name (qw(request_token request_token_secret)) {
my $value = $q->cookie($name);
$app->$name($value);
}
($tokens{'access_token'},
$tokens{'access_token_secret'}) =
$app->request_access_token(
callback => 'https://example.com/cgi-bin/goodreads-inject',
);
}
sub StartInjection {
my $at_cookie = new CGI::Cookie(-name=>'at',
-value => $tokens{'access_token'});
my $ats_cookie = new CGI::Cookie(-name => 'ats',
-value => $tokens{'access_token_secret'});
my $isbns_cookie = new CGI::Cookie(-name => 'isbns',
-value => '');
print $q->header(-cookie=>[$at_cookie,$ats_cookie,$isbns_cookie]);
print $q->start_html;
my $user_id = GetUserId();
if($user_id) {
my $shelf_id = LoughboroughShelf(user_id => $user_id);
if($shelf_id) {
my $isbns = $cookies{'isbns'}->value;
print $q->p("Got ISBNs list of $isbns");
AddBooksToShelf(shelf_id => $shelf_id,
isbns => $isbns,
);
}
}
print $q->end_html;
}
sub GetUserId {
my $user_id = 0;
my $response = $app->view_restricted_resource(
'https://www.goodreads.com/api/auth_user'
);
if($response->content) {
my $xml = XML::Mini::Document->new();
$xml->parse($response->content);
my $user_xml = $xml->toHash();
$user_id = $user_xml->{'GoodreadsResponse'}->{'user'}->{'id'};
}
return $user_id;
}
sub LoughboroughShelf {
my $params;
%{$params} = @_;
my $shelf_id = 0;
my $user_id = $params->{'user_id'} || return $shelf_id;
my $response = $app->view_restricted_resource('https://www.goodreads.com/shelf/list.xml?key=' . $tokens{'consumer_key'} . '&user_id=' . $user_id);
if($response->content) {
my $xml = XML::Mini::Document->new();
$xml->parse($response->content);
my $shelf_xml = $xml->toHash();
foreach my $this_shelf (@{$shelf_xml->{'GoodreadsResponse'}->{'shelves'}->{'user_shelf'}}) {
if($this_shelf->{'name'} eq 'loughborough-wishlist') {
$shelf_id = $this_shelf->{'id'}->{'-content'};
last;
}
}
if(!$shelf_id) {
$shelf_id = MakeLoughboroughShelf(user_id => $user_id);
}
}
print $q->p("Returning shelf id of $shelf_id");
return $shelf_id;
}
sub MakeLoughboroughShelf {
my $params;
%{$params} = @_;
my $shelf_id = 0;
my $user_id = $params->{'user_id'} || return $shelf_id;
my $response = $app->update_restricted_resource('https://www.goodreads.com/user_shelves.xmluser_shelf[name]=loughborough-wishlist',
);
if($response->content) {
my $xml = XML::Mini::Document->new();
$xml->parse($response->content);
my $shelf_xml = $xml->toHash();
$shelf_id = $shelf_xml->{'user_shelf'}->{'id'}->{'-content'};
print $q->p("Shelf hash: ".Dumper($shelf_xml));
}
return $shelf_id;
}
sub AddBooksToShelf {
my $params;
%{$params} = @_;
my $shelf_id = $params->{'shelf_id'} || return;
my $isbns = $params->{'isbns'} || return;
foreach my $isbn (split(',',$isbns)) {
my $response = $app->view_restricted_resource('https://www.goodreads.com/book/isbn_to_id?key=' . $tokens{'consumer_key'} . '&isbn=' . $isbn);
if($response->content) {
my $book_id = $response->content;
print $q->p("Adding book ID for ISBN $isbn is $book_id");
$response = $app->update_restricted_resource('http://www.goodreads.com/shelf/add_to_shelf.xml?name=loughborough-wishlist&book_id='.$book_id);
}
}
}
You’ll obviously need to get a developer consumer key and secret from the Goodreads site and pop them into the variables at the start of the script (no, I’m not sharing mine with you!). The real work is done by the StartInjection() subroutine and the subordinate subroutines that it then calls once the OAuth process has been completed. By this point we’ve got an access token and its associated secret so we can act as whichever user has allowed us to connect to Goodreads as them. The code will find this user’s Goodreads ID, see if they have a bookshelf called “loughborough-wishlist” (and create it if they don’t) and then add any books that Goodreads knows about with the given ISBN(s). You’d call this CGI script with a URL something like:
https://example.com/cgi-bin/goodreads-inject?isbns=9781565928282
Anyway, there’s a “works for me” simple example of talking to Goodreads from Perl using OAuth 1.0. There’s plenty of development work left in turning this into production level code (it needs to be made more secure for a start off, and the access tokens and secret could be cached in a file or database for reuse in subsequent sessions) but I hope some folk find this useful.
Originally the only content that was embedded in CLUMP was book covers and book previews/content available in Google Books. Access to other resources required users to follow links out of the system. Improving the content that can be embedded into CLUMP has always been something that we have wanted to tackle when we had the time.
When it comes to embedding content in a reading list we wanted to make it as easy as possible for the users. Most users have no problem using an embedded player, but adding one in some web systems can be very difficult. We could ask the user for specifics (like what site the content is on, what its unique id is, what format is the content in, etc.), but that would make it both awkward and time consuming for academics/librarians and force them to go back through their lists to update all the relevant resources. Also they would have to do that each time support was added for new embeddable content.
We also didn’t want to have specific embedded content types for list items as any content that can be embedded already fits into our existing content types. Adding extra metadata to the existing content types was also ruled out as this would make adding new items to lists far more cumbersome.
Our solution, that we have just implemented into our development version of CLUMP, is that embeddable content should be identified and handled by the system. It should recognise when a item’s URL points to a resource that it can embed and then take the necessary steps to embed the content. This way, not only is it easy for academics/librarians to add embedded content, but existing resources will start having their content embedded in their item level popups without anyone having to make any changes to the metadata.
New resource that will appear as embedded content include both YouTube and Vimeo videos, any video files in mp4, WebM and ogv formats and any audio files in a mp3, wav or ogg format. The YouTube and Vimeo content use their embedded players to display the content, while the video and audio files use the HTML5 video and audio tags to provide the user with a player in the browser without needing any additional plugins.
Using the the HTML5 video and audio capabilities has both pros and cons. Not needing to include any plugins is an advantage, especially with the increasing number of devices that don’t support flash content. Conversely though older browsers suffer from lack of support for the new tags and so won’t display the content, also each browsers that does support the tags supports them for a different range of media types.
Luckily when a browser doesn’t support the tags or the media type of the resource it doesn’t produce an error, it just doesn’t show the embedded content. Of course if the users browser doesn’t support any of the embedded content they can still use the URL to access/download the content.
Having a reading list management system has a number of advantages, including providing the Library with better management information to help manage its stock. At Loughborough we’ve been working a couple of scripts that tie LORLS into our Aleph library management system. These are pretty “bespoke” and probably won’t form part of the normal LORLS distribution as they rely on quite a bit on the local “information landscape” here, but it might be useful to describe how they could help.
A good example is our new high demand items report. This script (or rather interlinked set of scripts as it runs on several machines to gather data from more than one system) tries to provide library staff with a report of items that have recently been in high demand, and potentially provide hints to both them and academics about reading lists that might benefit from these works being added.
The first part of the high demand system goes off to our Aleph server to peer into both requests for items and loan information. We want to look for works that have more than a given number of hold requests placed on them in a set time period and/or more than a threshold number of simultaneous loans made. These parameters are tunable and the main high demand script calls out via an XML API to another custom Perl script that lives on Aleph server that does the actual Oracle SQL jiggery-pokery. This is actually quite slow – its trawling through a lot of data potentially (especially if the period of time that the query is applied over is quite long – we tended to limit queries to less than a week usually otherwise the whole process can take many hours to run).
This script returns a list of “interesting” items that match our high demand criteria and the users that have requested and/or borrowed them. The main script can then use this user information to look up module membership. It does this using LDAP queries to our Active Directory servers, as every module appears as a group in the AD with users being group members. We can then look for groups of users interested in a particular item that share module membership. If we get more than a given (again tunable) number we check if this work is already mentioned on the reading list for the module and, if not, we can optionally make a note about the work’s ISBN, authors, title, etc into a new table. This can then be used in the CLUMP academic dashboard to show suggestions about potentially useful extra works that might be suitable for the reading list.
The main script then marshals the retrieved data and generates an HTML table out of it, one row for each work. We include details of ISBN, author, title, shelfmark, number of active reservations, maximum concurrent loans, the different types of loan, an average price estimate (in case extra copies may be required) and what reading lists (if any) the work is already on. We can also optionally show the librarians a column for the modules that users trying to use this work are studying, as well as two blank columns for librarians to make their own notes in (when printed out – some still like using up dead trees!).
The main script can either be run as a web based CGI script or run from the command line. We mostly use the latter (via cron) to provide emailed reports, as the interactive CGI script can take too long to run as mentioned earlier. It does demonstrate how reading lists, library management systems and other University registration systems can work together to provide library staff with new information views on how stock is being used and by who.
It has been a while since I posted any updates on improvements to CLUMP (the default interface to LORLS) and as we have just started testing the latest beta version, it seemed a good time to make a catch up post. So other than the Word export option, what other features have been introduced?
With the addition of sub-headings in version 7 of LORLS it soon become obvious that we needed to improve the logic of our list sorting routines as they were no longer intuitive. Historically our list sorting routines have treated the list as one long list (as without sub-headings there was no consistent way to denote a subsection of a list other than using a sub-list).
The new sorting logic is to break the list into sections and then sort within each section. In addition to keeping the ordering of the subsections any note entries at the top of a section are considered to be sticky and as such won’t be sorted.
Finally if there are any note entries within the items to be sorted the user is warned that these will be sorted with the rest of the subsections entries.
Another area that we have been investigating is suggestions to list owners for items they might want to consider for their lists. The first stage of this it the inclusion of a new question on the dashboard, “Are there any suggested items for this list?”. When the user clicks on this question they are shown a list of suggested articles based upon ExLibris’s bX recommender service.
To generate the article suggestions current articles on the list are taken and bX queried for recommendations. All of the returned suggestions are sorted so the at the more common recommendations are suggested first.
CLUMP now has a set of basic styles and configurations that are used as the default options. These defaults are then over-ridden by the theme in use. This change was required to make the task of maintaining custom themes easier. Where previously, missing entries in a customised theme would have to be identified and updated by hand before the theme could be used, now those custom themes will work as any missing entries will fall back to using the system default.
One annoyance with CLUMP has been that due to being AJAX based the back button would take users to the page they were on before they started looking at the system rather than the Department, Module, List they were looking at previously. This annoyance has finally been removed by using the hash-ref part of the URL to identify the structural unit currently being viewed.
Every time the user views a new structural unit the hash-ref is updated with its ID. Instead of reloading the page when the user or browser changes the hash-ref (e.g. through clicking the back button) a JavaScript event is triggered. The handler attached to this event parses the hash-ref and extracts the structural unit ID which is used to display the relevant structural unit.
For a while now we’ve been feverishly coding away at the top secret LORLS bunker on a new library management tool attached to LORLS: a system to help predict which books a library should buy and roughly how many will be required. The idea behind this was that library staff at Loughborough were spending a lot of time trying to work out what books needed to be bought, mostly based on trawling through lots of data from systems such as the LORLS reading list management system and the main Library Management System (Aleph in our case). We realised that all of this work was suitable for “mechanization” and we could extract some rules from the librarians about how to select works for purchase and then do a lot of the drudgery for them.
We wrote the initial hack-it-up-and-see-if-the-idea-works-at-all prototype about a year ago. It was pretty successful and was used in Summer 2012 to help the librarians decide how to spend a bulk book purchasing budget windfall from the University. We wrote up our experiences with this code as a Dlib article which was published recently. That article explains the process behind the system, so if you’re interested in the basis behind this idea its probably worth a quick read (or to put it in other terms, I’m too lazy to repeat it here! 😉 ).
Since then we’ve stepped back from the initial proof of concept code and spent some time re-writing it to be more maintainable and extensible. The original hacked together prototype was just a single monolithic Perl script that evolved and grew as we tried ideas out and added features. It has to call out to external systems to find loan information and book pricing estimates with bodges stuffed on top of bodges. We always intended it to be the “one we threw away” and after the summer tests it became clear that the purchase prediction could be useful to the Library staff and it was time to do version 2. And do it properly this time round.
The new version is modular… using good old Perl modules! Hoorah! But we’ve been a bit sneaky: we’ve a single Perl module that encompasses the purchase prediction process but doesn’t actually do any of it. This is effectively a “wrapper” module that a script can call and which knows about what other purchase prediction modules are available and what order to run them in. The calling script just sets up the environment (parsing CGI parameters, command line options, hardcoded values or whatever is required), instantiates a new PurchasePrediction object and repeatedly calls that object’s DoNextStep() method with a set of input state (options, etc) until the object returns an untrue state. At that point the prediction has been made and suggestions have, hopefully, been output. Each call to DoNextStep() runs the next Perl module in the purchase prediction workflow.
The PurchasePrediction object comes with sane default state stored within it that provides standard workflow for the process and some handy information that we use regularly (for example ratios of books to students in different departments and with different levels of academic recommendation in LORLS. You tend to want more essential books than you do optional ones obviously, whilst English students may require use of individual copies longer than Engineering students do). This data isn’t private to the PurchasePredictor module though – the calling script could if it wished alter any of it (maybe change the ratio of essential books per student for the Physics department or even alter the workflow of the purchase prediction process).
The workflow that we currently follow by default is:
Each of those steps is broken down into one or more (mostly more!) separate operations, with each operation then having its own Perl module to instantiate it. For example to acquire ISBNs we’ve a number of options:
Which of these will do anything depends on the input state passed into the PurchasePredictor’s DoNextStep() method by the calling script – they all get called but some will just return the state unchanged whilst others will add new works to be looked at later by subsequent Perl modules.
Now this might all sound horribly confusing at first but it has big advantages for development and maintenance. When we have a new idea for something to add to the workflow we can generate a new module for it, slip it into the list in the PurchasePredictor module’s data structure (either by altering this on the fly in a test script or, once the new code is debugged, altering the default workflow data held in the PurchasePredictor module code) and then pass some input to the PurchasePredictor module’s DoNextStep() method that includes flags to trigger this new workflow.
For example until today the workflow shown in the second list above did not include the step “Find ISBNs from reading list works that have been edited within a set number of days”; that got added as a new module written from scratch to a working state in a little over two hours. And here’s the result, rendered as an HTML table:
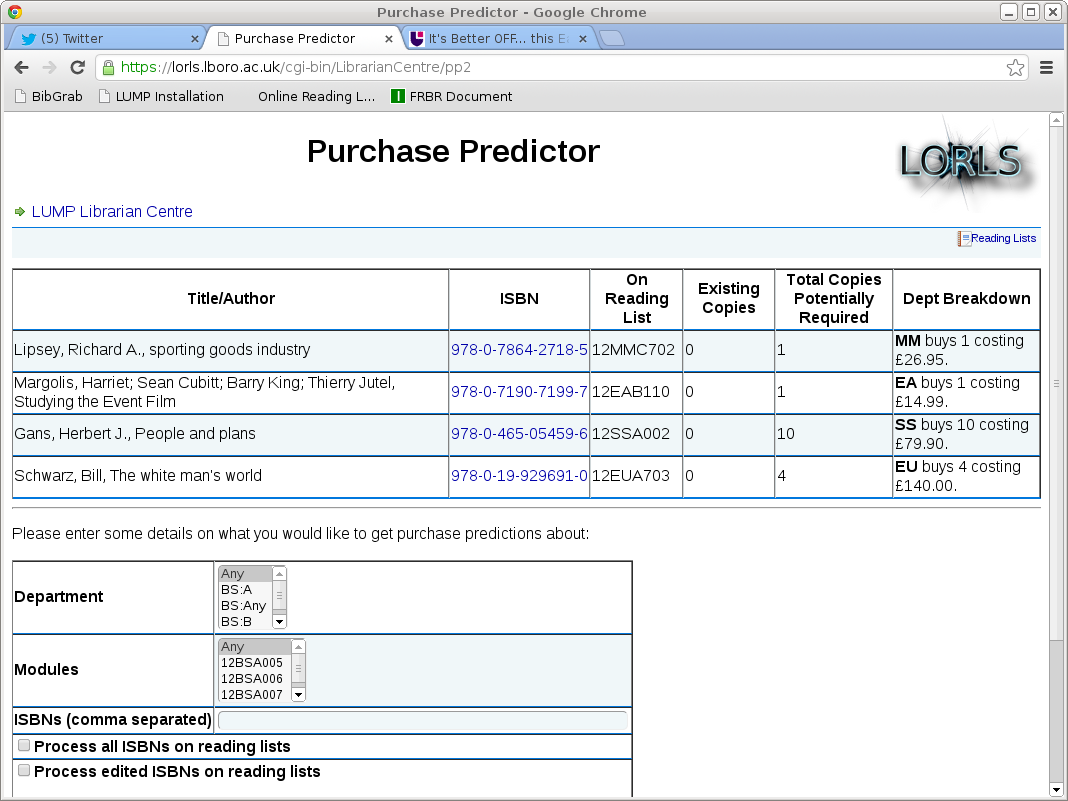
Purchase Predictor pp2 HTML showing suggested purchases for works in LORLS edited in the last day.
As you can see the purchase predictor HTML output in this case tries to fit in with Jason’s new user interface, which it can do easily as that’s all encompassed in Perl modules as well!
There’s still lots more work we’ve can do with purchase prediction. As one example, the next thing on my ‘To Do’ list is to make an output module that generates emails for librarians so that it can be run as batch job by cron every night. The librarians can then sip their early morning coffee whilst pondering which book purchasing suggestions to follow up. The extensible modular scheme also means we’re free to plug in different actual purchasing algorthims… maybe even incorporating some machine learning, with feedback provided by the actual purchases approved by the librarians against the original suggestions that the system made.
I knew those undergraduate CompSci Artificial Intelligence lectures would come in handy eventually… 🙂