Loughborough Online Reading List System
CLUMP
A Newcomer’s guide to installing “LORLS In A Box”
As has been mentioned in this blog before, back in the days when the MALS team was still the Library Systems team, they developed the Loughborough Online Reading List System (LORLS) to manage the resources for directed student reading.
A recent rebranding of the University’s Library online presence means we now have a requirement to change the styling of our local installation of LORLS. I am still relatively new to the team and as yet have not had cause to look at the front end of LORLS, known affectionately as CLUMP, and this seemed like an ideal introduction for me.
So where better to start than with the documentation the team already put together. My first port of call is the installation instructions where I discover that some thoughtful techie has already built me a VM to play with. Reading through the guide to the VM you can tell the techie in question was Jon, the passwords used are a good clue but the giveaway is the advice to make a cup of tea and eat a biscuit whilst waiting for the download.
The download and subsequent import into Virtual Box seem to happen with a minimum of fuss but here is where I make my first rookie mistake as I choose to reinitialise the MAC address of all network interfaces.
CentOS maintains a mapping of MAC address to interface IDs and so it spots that the VM no longer has the MAC address it associated with eth0 but does have an entirely new MAC address which it associates with eth1. The configuration of the VMs NIC is tied to eth0 and so I don’t have a working network connection.
This is quick and easy to fix. First I head to /etc/sysconfig/network-scripts where I rename the file ifcfg-eth0 to ifcfg-eth1 (this is not essential but helps with sanity). I then edit this file and change the DEVICE value to be eth1 and update the HWADDR value to be the new MAC address which can be found using ifconfig -a. Restart the network service and all is well.
Of course if you don’t reinitialise the MAC address when importing the VM then you shouldn’t see this issue and it should just work straight away.
When starting the VM, as described in Jon’s instructions, displayed above the login prompt I am shown the IP address assigned to the VM by DHCP and the URL for my LORLS instance. Plugging these into my browser takes me to a vanilla installation of LORLS running on my VM. One note here, be sure to type CLUMP and not clump it is case sensitive.
So all pretty straightforward to get up and running, in fact I am pleased I made the mistake with the MAC address as there would have been little of note to write about otherwise. Now onto setup and customisation but I may save that for another “Newcomer’s guide to LORLS” blog post in the future.
The continuing battle of parsing Word documents for reading list material
15 Jul 2015
At this year’s Meeting The Reading List Challenge (MTLRC) workshop, Gary Brewerton (my boss) showed the delegates one of our LORLS features: the ability to suck citation data out of Word .docx documents. We’ve had this for a few years and it is intended to allow academics to take existing reading lists that they have produced in Word and import them relatively easily into our electronic reading lists system. The nice front end was written by my colleague Jason Cooper, but I was responsible for the underlying guts that the APIs call to try parsing the Word document and turn it into structured data that LORLS can understand and use. We wrote it originally based on suggestions from a few academics who already had reading lists with Harvard style references in them, and they used it to quickly populate LORLS with their data.
Shortly after the MTRLC workshop, Gary met with some other academics who also needed to import existing reading lists into LORLS. He showed them our existing importer and, whilst it worked, it left quite alot entries as “notes”, meaning it couldn’t parse them into structured data. Gary then asked me to take another look at the backend code and see if I could improve its recognition rate.
I had a set of “test” lists donated by the academics of varying lengths, all from the same department. With the existing code, in some cases less than 50% of the items in these documents were recognised and classified correctly. Of those, some were misclassified (eg book chapters appearing as books).
The existing LORLS .docx import code used Perl regular expression pattern matching alone to try to work out what sort of work a citation referred to this. This worked OK with Word documents where the citations were well formed. A brief glance through the new lists showed that lots of the citations were not well formed. Indeed the citation style and layout seemed to vary from item to item, probably because they had been collected over a period of years by a variety of academics. Whilst I could modify some of the pattern matches to help recognise some of the more obvious cases, it was clear that the code was going to need something extra.
That extra turned out to be Z39.50 look ups. We realised that the initial pattern matches could be quite generalised to see if we could extract out authors, titles, publishers and dates, and then use those to do a Z39.50 look up. Lots of the citations also had classmarks attached, so we’d got a good clue that many of the works did exist in the library catalogue. This initial pattern match was still done using regular expressions and needed quite a lot of tweaking to get recognition accuracy up. For example spotting publishers separated from titles can be “interesting”, especially if the title isn’t delimited properly. We can spot some common cases, such as publishers located in London, New York or in US states with two letter abbreviations. It isn’t fool proof, but its better than nothing.
However using this left us with only around 5% of the entries in the documents classified as unstructured notes when visual checking indicated that they were probably citations. These remaining items are currently left as notes, as there are a number of reasons why the code can’t parse them.
The number one reason is that they don’t have enough punctuation and/or formatting in the citation to allow regular expression to determine which parts are which. In some cases the layout doesn’t even really bear much relation to any formal Harvard style – the order of authors and titles can some time switch round and in some cases it isn’t clear where the title finishes and the publisher ends. In a way they’re a good example to students of the sort of thing they shouldn’t have in their own referencing!
The same problems encountered using the regular expressions would happen with a formal parser as these entries are effectively “syntax errors” if treating Harvard citations as a sort of grammar. This is probably about the best we’ll be able to do for a while, at least until we’ve got some deep AI that can actually read the text and understand it, rather that just scan for patterns.
And if we reach that point LORLS will probably become self aware… now there’s a scary thought!
Enhancing the look and feel of tables
23 Jul 2014
by Jason Cooper
in CLUMP
Recently we have looked at improving some of the tables in CLUMP. At first we thought that it would involve quite a bit of work, but then we came across the DataTables jQuery plugin. After a couple of days of coding we’ve used it to enhance a number of tables on our development version of CLUMP. Key features that attracted us to it are:
Licencing
DataTables is made available under an MIT Licence, so it is very developer friendly.
Easy to apply to existing tables
As one of the many data sources that DataTables supports is the DOM you can use it to quickly enhance an existing table.
Pagination
Sometimes a long table can be unwieldy, with the pagination options in DataTables you can specify how many entries to show by default and how the next/previous page options should be presented to the user. Of Course you can disable the pagination to display the data in one full table.
Sortable columns
One of the most useful features DataTables has is its ability to allow the user to order the table by any column by simply clicking on that column’s header, an action that has become second nature to a lot of users. It’s also possible to provide custom sorting functions for columns if the standard sorting options don’t work for the data they contain.
Instant search
As users type their search terms into the search box DataTables hides table rows that don’t meet the current search criteria.
Extensible
There are a number of extensions available for DataTables that enhance its features, from allowing users to reorder the column by dragging their headers about, to adding the option for users to export the table to the clipboard or exporting it as a CSV, XLS or even a PDF.
Very Extensible
If you have some bespoke functionality required then you can use its plug-in Architecture to create your own plugin to meet it.
Embedding content
19 Nov 2013
Originally the only content that was embedded in CLUMP was book covers and book previews/content available in Google Books. Access to other resources required users to follow links out of the system. Improving the content that can be embedded into CLUMP has always been something that we have wanted to tackle when we had the time.
When it comes to embedding content in a reading list we wanted to make it as easy as possible for the users. Most users have no problem using an embedded player, but adding one in some web systems can be very difficult. We could ask the user for specifics (like what site the content is on, what its unique id is, what format is the content in, etc.), but that would make it both awkward and time consuming for academics/librarians and force them to go back through their lists to update all the relevant resources. Also they would have to do that each time support was added for new embeddable content.
We also didn’t want to have specific embedded content types for list items as any content that can be embedded already fits into our existing content types. Adding extra metadata to the existing content types was also ruled out as this would make adding new items to lists far more cumbersome.
Our solution, that we have just implemented into our development version of CLUMP, is that embeddable content should be identified and handled by the system. It should recognise when a item’s URL points to a resource that it can embed and then take the necessary steps to embed the content. This way, not only is it easy for academics/librarians to add embedded content, but existing resources will start having their content embedded in their item level popups without anyone having to make any changes to the metadata.
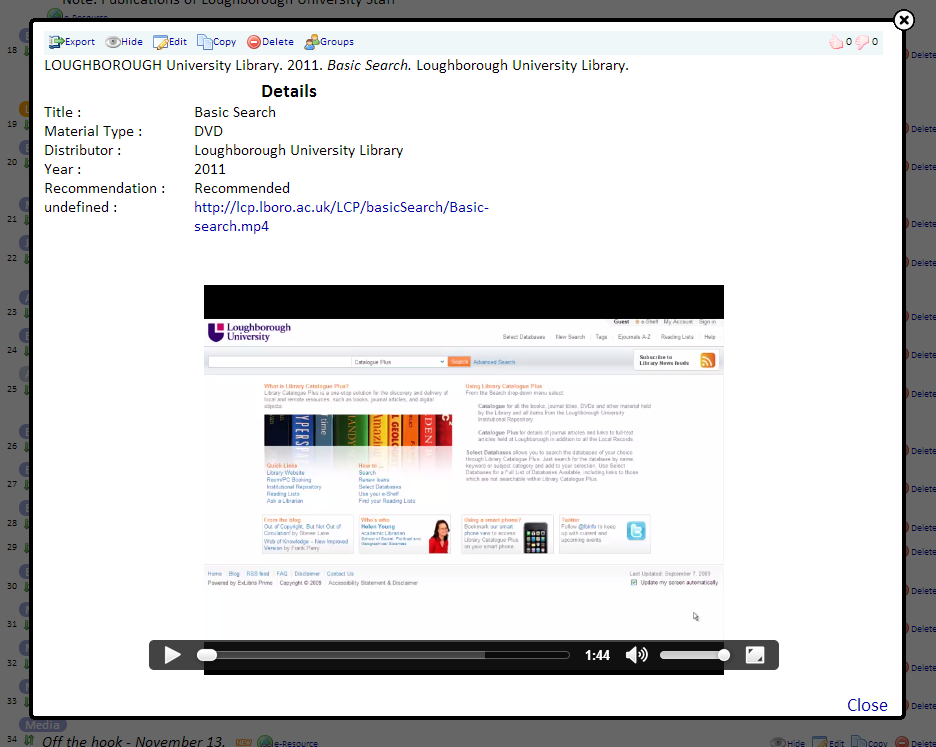
New resource that will appear as embedded content include both YouTube and Vimeo videos, any video files in mp4, WebM and ogv formats and any audio files in a mp3, wav or ogg format. The YouTube and Vimeo content use their embedded players to display the content, while the video and audio files use the HTML5 video and audio tags to provide the user with a player in the browser without needing any additional plugins.
Using the the HTML5 video and audio capabilities has both pros and cons. Not needing to include any plugins is an advantage, especially with the increasing number of devices that don’t support flash content. Conversely though older browsers suffer from lack of support for the new tags and so won’t display the content, also each browsers that does support the tags supports them for a different range of media types.
Luckily when a browser doesn’t support the tags or the media type of the resource it doesn’t produce an error, it just doesn’t show the embedded content. Of course if the users browser doesn’t support any of the embedded content they can still use the URL to access/download the content.
CLUMP Improvements
04 Jun 2013
It has been a while since I posted any updates on improvements to CLUMP (the default interface to LORLS) and as we have just started testing the latest beta version, it seemed a good time to make a catch up post. So other than the Word export option, what other features have been introduced?
Advanced sort logic
With the addition of sub-headings in version 7 of LORLS it soon become obvious that we needed to improve the logic of our list sorting routines as they were no longer intuitive. Historically our list sorting routines have treated the list as one long list (as without sub-headings there was no consistent way to denote a subsection of a list other than using a sub-list).
The new sorting logic is to break the list into sections and then sort within each section. In addition to keeping the ordering of the subsections any note entries at the top of a section are considered to be sticky and as such won’t be sorted.
Finally if there are any note entries within the items to be sorted the user is warned that these will be sorted with the rest of the subsections entries.
Article suggestions
Another area that we have been investigating is suggestions to list owners for items they might want to consider for their lists. The first stage of this it the inclusion of a new question on the dashboard, “Are there any suggested items for this list?”. When the user clicks on this question they are shown a list of suggested articles based upon ExLibris’s bX recommender service.
To generate the article suggestions current articles on the list are taken and bX queried for recommendations. All of the returned suggestions are sorted so the at the more common recommendations are suggested first.
Default base for themes
CLUMP now has a set of basic styles and configurations that are used as the default options. These defaults are then over-ridden by the theme in use. This change was required to make the task of maintaining custom themes easier. Where previously, missing entries in a customised theme would have to be identified and updated by hand before the theme could be used, now those custom themes will work as any missing entries will fall back to using the system default.
The back button
One annoyance with CLUMP has been that due to being AJAX based the back button would take users to the page they were on before they started looking at the system rather than the Department, Module, List they were looking at previously. This annoyance has finally been removed by using the hash-ref part of the URL to identify the structural unit currently being viewed.
Every time the user views a new structural unit the hash-ref is updated with its ID. Instead of reloading the page when the user or browser changes the hash-ref (e.g. through clicking the back button) a JavaScript event is triggered. The handler attached to this event parses the hash-ref and extracts the structural unit ID which is used to display the relevant structural unit.
Exporting to a Word document
08 Mar 2013
A new feature we have been working on in our development version of CLUMP, is the option for a list editor to export their reading list as a word document (specifically in a docx format). This will be particularly beneficial for academics extract a copy of their list in a suitable format for inclusion into a course/module handbook. A key requirement we had when developing it was that it should be easy to alter the styles used for headings, citations, notes, etc.
As previously mentioned by Jon the docx format is actually a zip file containing a group of XML files. The text content of a document is stored within the “w:body” element in the document.xml file. The style details are stored in another of the xml files. Styles and content being stored in separate files allows us to create a template.docx file in word, in which we define our styles. The export script then takes this template and populates it with the actual content.
When generating an export the script takes a copy of the template file, treats it as a zip file and extracts the document.xml file. Then it replaces the contents of the w:body element in that extracted file with our own xml before overwriting the old document.xml with our new one. Finally we then pass this docx file from the servers memory to the user. All of this process is done in memory which avoids the overheads associated with generating and handling temporary files.
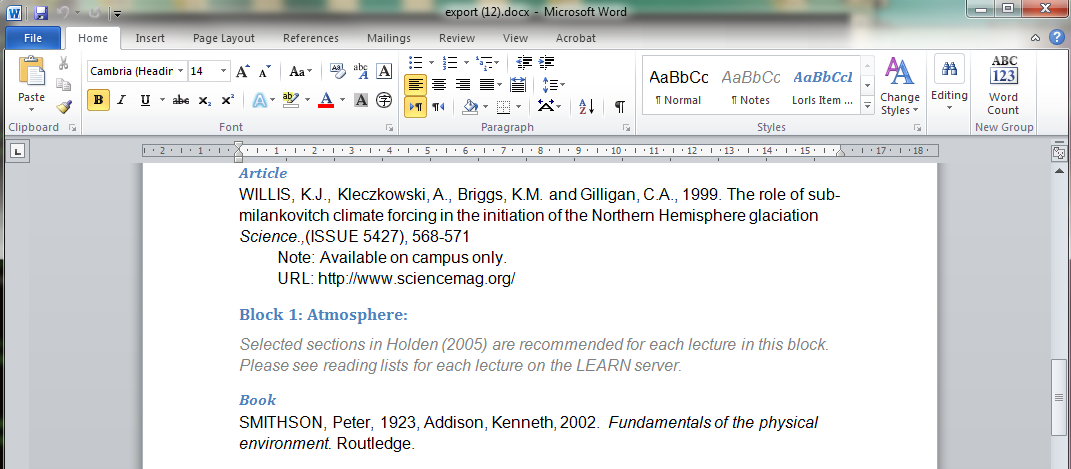
To adjust the formatting of the styles in the template it can simply be loaded into Word, where the desired changes to the styles can be made. After it has been saved it can be uploaded to the server to replace its existing template.
Trouble installing? Disable SELinux
13 Nov 2012
We are currently working on a new distribution of LORLS (That’s right version 7 is coming soon) and to test the installer’s ability to update an existing installation we needed a fresh v6 install to test on. So I dropped into a fresh virtual machine we have dedicated specifically to this kind of activity, downloaded the version 6 installer and ran through the installation only to find that, while it had created the database and loaded the initial test data just fine, it hadn’t installed any of the system files.
So for the next 3 hours I was scouring apache’s logs, checking the usual culprits for these sort of issues and debugging the code. One of the first things I did was check the SELinux configuration and it was set to permissive, which means that it doesn’t actually block anything just warns the user. This lead me to discount SELinux as the cause of the problem.
After 3 hours of debugging I finally reached the stage of having a test script that would work when run by a user but not when run by apache. The moment that I had this output I realised that while SELinux may be configured to be permissive, it will only pick up this change when the machine is restarted. So I manually tried disabling SELinunx (as root use the command ‘echo 0 > /selinux/enforce’) and then tried the installer again.
Needless to say the installer worked fine after this, so if you are installing LORLS and find that it doesn’t install the files check that SELinux is disabled.
Academic dashboard in beta
22 Jun 2012
 One area of discussion at last year’s Meeting the reading list challenge workshop was around the sort of statistics that academics would like about their reading lists. Since then we have put the code in to log views of reading lists and other bits of information.
One area of discussion at last year’s Meeting the reading list challenge workshop was around the sort of statistics that academics would like about their reading lists. Since then we have put the code in to log views of reading lists and other bits of information.
2 months ago, having collected 10 months of statistics we decided to put together a dashboard for owners of reading lists. The current beta version of the dashboard contains the following information
- Summary – a quick summary of the list and the type of content on it
- Views of the reading list – how many people have viewed the list
- URLs – Details of the number of items on the list with a URL, and details of any URLs that appear to be broken (with a option to highlight those items with broken URLs on the reading list)
- Best rated items – the top user rated item on the list (again with an option to highlight those items on the reading list)
- Worst rated items – the lowest user rated items on the list (yet again with an option to highlight those items on the reading list)
- Item Composition – a graphical representation of the types of items on the reading list
- Item Loans – a graph showing the number of items from the reading list loaned out by the Library over the past year.

Big changes under the hood and a couple of minor ones above
22 May 2012
A few weeks ago we pushed out an update to our APIs on our live instance of LORLS and this morning we switched over to a new version of our front end (CLUMP). The changes introduced in this new version are the following
- Collapsible sub-headings
- Improved performance
- Better support for diacritics
Collapsible sub-headings
Following a suggestion from an academic we have added a new feature for sub-headings. Clicking on a sub-heading will now collapse all the entries beneath it. To expand the section out again the user simple needs to click on the sub heading again. This will be beneficial to both academics maintaining large lists and students trying to navigate them.
Improved performance
In our ever present quest to improve the performance, both actual and perceptual, we decided to see if using JSON instead of XML would help. After a bit of experimentation we discovered that using JSON and JSONP would both reduced the quantity of JavaScript code in CLUMP’s routines and significantly improved the performance.
Adjusting Jon’s APIs in the back end (LUMP) to return in either XML, JSON or JSONP format was quite easy once the initial code had been inserted in the LUMP module’s respond routine. Then it was simply a matter of adding 4 lines of code to each API script.
Switching CLUMP to using JSONP was a lot more time consuming. Firstly every call had to have all it’s XML parsing code removed and then the rest of the code in the routine needed to be altered to use the JavaScript object received from the API. This resulted in both nicer to code/read JavaScript and smaller functions.
Secondly a number of start up calls had been synchronous, so the JavaScript wouldn’t continue executing until the response from the server had been received and processed. JSONP calls don’t have a synchronous option. The solution in the end was to use a callback from the function that processes the JSONP response from the server and with a clever bit of coding this actually enabled us to make a number of calls in parallel and continue only after all of them had completed. Previously the calls were made one after the other, each having to wait for the preceding call to have been completed before it could start. While this only saved about half a second on the start up of CLUMP, it made a big difference to the user perception of the systems performance.
Better support for diacritics
This was actually another beneficial side-effect of switching to JSONP over XML for most of our API calls. In Internet Explorer it was discovered that some UTF-8 diacritic characters in the data would break its XML parser, but because JSONP doesn’t use XML these UTF-8 characters are passed through and displayed fine by the browser. Of course we do sometimes find some legacy entries in a reading list, created many years ago in a previous version of LORLS, which are in the Latin-1 character set rather than UTF-8, but even these don’t break the JavaScript engine (though they don’t necessarily display the character that they should).
Item Ratings
30 Apr 2012
One of the things on the LORLS “to do” list from last summer’s Meeting the Reading Lists Challenge workshop was to have ratings on lists and/or items. Gary and I had a chat about this earlier today and decided that if we’re going to do it, it would probably be better just on items rather than lists. That way students are commenting on how useful they found individual books, articles, etc rather than the academics reading list as a whole, so there would probably be more acceptance from academics.
I’ve thus produced two new API calls to support this:
- GetSURating – get the ratings for particular structural units and/or users. If you give it a “suid” parameter with a comma separated list of structural unit IDs it will try to find ratings for those. You can also ask for rating set by one or more users by specifying the “user_id” parameter with a comma separate list of user IDs (the latter mostly because I thought we might want to allow folk in the future to see which books they’d rated, a bit like LibraryThing does). The script normally returns some XML with the ratings for each matched SUID (good and bad). You can give it a “details” parameter set to ‘Y’ in which case it will just splurge out XML with all the matching records in (including creation/modification times, etc so we could do fancy time based rating analysis).
- Editing/EditSURating – create/edit a rating. Needs to have the structural unit ID send in via the “suid” parameter and the rating itself (either “Good” or “Bad”) via the “rating” parameter. No user_id parameter as it takes the logged in user as the person to create the rating from. It returns a summary of the current ratings for the structural unit after updating for this user. If you’re not logged in it does nothing.
Each user can click on ratings for a particular structural unit as many times as they like, but they’ll only have one active record. That means that you can rate something as “Bad” at first, then re-read it later and decide that you were wrong and its actually “Good” and re-rate it. Your old “Bad” rating is replaced by the “Good” rating.
We’ve already been talking about how we can make use of the data once the students start rating items. For example we could have a graph or scatter chart in the academic’s dashboard showing them four quadrants: rarely borrowed items that aren’t liked, rarely borrowed items that are liked, heavily borrowed items that aren’t liked and heavily borrowed items that are liked. This would provide some feedback to academics on how useful the students found the material on their reading lists, and would also potentially supply some useful information to library staff. You could imagine that a very expensive book that the library has put off buying a copy of but which is heavily liked by people who’ve acquired/seen copies elsewhere might persuade library staff to order a copy for instance.
I’ve got a proof of concept up and running now on our test/dev server. This shows thumbs up/down on the bibiographic details popup in CLUMP for leaf items (books, journals, etc). As it requires a change to the LUMP database schema (in fact a whole new user_item_rating table), this isn’t going to be a LORLS v6.x thing but instead a LORLS v7 feature.
Oh crumbs, I’ve started working on the next version of LORLS already! 🙂