
I’m going to start this blog post with a “user story” – the sort of thing that we use to shape systems design. Then I’ll talk about one aspect of the design that this user story gave rise to, and the resulting fun with hacking on Shibboleth and cross site scripting. But first the user story:
User story
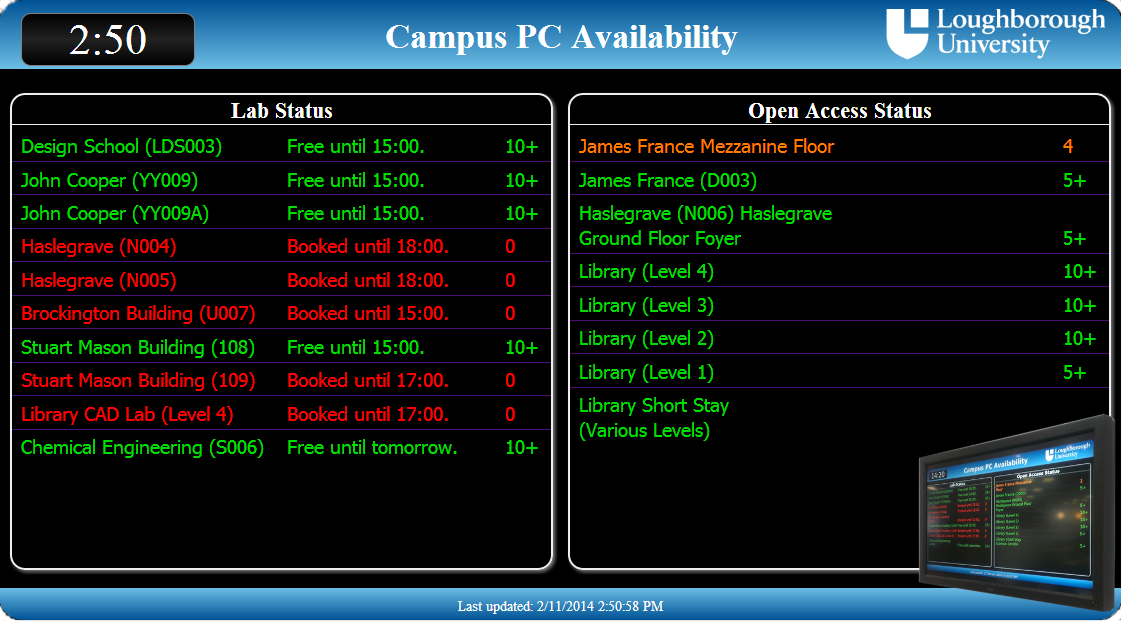
We have computer labs on campus, some of which are public (any members of the institution can use them) and some of which are “private” – only available for staff and students in certain groups (departments or modules for example). The campus is large, with long walks between buildings so students (and to some extent staff) would like to know which labs have machines that are available for them to drop in and use. To complicate matters some labs are also bookable for classes, during which time no machines are available for drop in use.
The University is also very keen on using single sign on technologies to minimise the number of times that our users are prompted for their username and password. We use Shibboleth and simpleSAMLphp to provide this on campus, and where possible new services should make use of this technology and avoid popping up unnecessary log in dialogues.
In this case we would like to provide a view of machine availability in the public labs for people that have not authenticated, and a tailored view for people that have got an existing Shibboleth session running. We also need to make this available in a dynamic HTML page using RESTful APIs because some departments may wish to take the data and mash it up into their own displays and reporting systems.
Shibboleth and APIs
OK, so that’s our user story – the reason why we’re going to need to write some code. Most of the API details aren’t important here – they just talk to back end databases that are populated regularly with details of labs, machine availability and bookings. The APIs then format the data into some nice JSON output that the Javascript on the client can turn into pretty HTML.
However we need to tailor the output for the user if they have already authenticated and have active Shibboleth sessions running so that we can show them specific information about the private labs they have access to. To do this from client side Javascript is we need to know what username (if any) a Shibboleth session is associated with, so that we can then provide a list of the labs that this person has access to using other API calls.
The obvious first approach was to write a simple CGI API script on a web server that has Apache and mod_shib installed. The CGI script would be called from the client side Javascript and would get the user’s eppn or cn details. These come from the environment variables that mod_shib provides. The CGI script would return them in a JSON structure for the client side code to then use. The resulting script is quite simple:
#!/usr/bin/perl
use strict;
use JSON;
print "Content-type: application/json\r\n\r\n";
my $output = {};
foreach my $env_var ('cn', 'eppn') {
if($ENV{$env_var}) {
$output->{$env_var} = $ENV{$env_var};
}
}
my $json = new JSON;
print $json->pretty->encode($output);
The first problem with this is that we also need to support people who aren’t logged in. This appeared to mean that we couldn’t use the common Apache mod_shib config that we use with our other server side Shibbolized CGI script:
<Location /cgi-bin/somewhere/whoami>
AuthType shibboleth
ShibRequestSetting requireSession 1
require valid-user
<Location>
Not to worry though: reading the Shibboleth documentation there is an option for “passive” or “lazy” authentication. This means that if a Shibboleth session is active, mod_shib makes use of it to fill in the environment variables with user details as before and approves running the CGI script. Otherwise it just passes authentication back to Apache which can then run the CGI script without the additional Shibboleth variables in the environment. All we need to do is remove the “require valid-user” and change the 1 to a 0 for the requireSession setting. Sounds just what we want, right?
Wrong. What passive Shibboleth authentication lacks is the ability to check with the IdP if there is an existing Shibboleth session known to the web browser that wasn’t made to our web server. Effectively it allows “guest” access to the CGI script, with the option of going through an manual IdP login process if the user wishes to for that one site. Not that it really matters, as it soon became apparent that there were other issues with doing Shibbolized API calls from Javascript.
XMLHttpRequest and CORS
OK, so passive authentication in Shibboleth isn’t going to help much here. Lets step back a moment, and put the normal, non-passive mod_shib configuration shown above back in place. If the user has a valid Shibboleth session running, this should give us their user details, otherwise they’ll get an HTML page from the IdP asking them to log in.
However, we want to use this CGI script as an API from Javascript, so we’re going to be calling it using the XMLHttpRequest object’s methods. Maybe we could make the call and then see what the returned document is? If its JSON with cn or eppn details we know the user is logged in via Shibboleth. If its an HTML page of some sort, its probably a login or error page from the IdP intended to be displayed to the user, so we know they aren’t logged in.
Now, when we call the API CGI script from XMLHttpRequest we’re actually going to end up with a set of HTTP 302 redirects from the API’s server to the IdP server and possibly back again. Effectively one call to a Shibbolized resource may end up as multiple HTTP transactions. This is where Shibboleth stops playing nicely because of cross domain security in Javascript in web browsers:
- Cookies can not be set on the request, and often don’t propagate across the 302 redirects if a server attempts to set them with a Set-Cookie: HTTP header.
- We can’t intercept any of the 302 redirects in Javascript to try to inject headers or cookies. The browser will do those redirects itself until it hits of 200, 500, 403, etc response from a web server.
- By default, XMLHttpRequest ignores the output if the responding server doesn’t match the Origin of the request (ie the server where the Javascript came from originally).
W3C have been working on Cross-Origin Resource Sharing (CORS) technologies. These can help with some of these issues. For example web servers can issues a Access-Control-Allow-Origin HTTP Header which says which allows suitably equipped modern browsers to over come the Origin checking. However these are limited: your server can only have one Access-Control-Allow-Origin header value, otherwise browser Javascript interpreters will throw an error. You can specify “*” for the Access-Control-Allow-Origin header value which gives a wild card match against any Origin, but we found that if you do that browsers then disallow the passing of credentials (including cookies).
So, calling a Shibbolized API from XMLHttpRequest looks like a non-starter. Every time a hand seems to reach out to help us, another hand comes along and slaps us down. We need to be sneakier and… well, cruftier.
Evil iframe Hacking
Let me just say up front: iframes are ugly, are a hack and I’d rather not use them.
However they do offer us the sneaky solution to this problem in that they don’t appear to have some of the restrictions that the XMLHttpRequest calls do. Specifically they appear to set cookies for a remote web server based on ones know to the browser and also honour cookie setting during HTTP 302 redirects.
What we can do is create a hidden iframe dynamically using client side Javascript, set an onLoad() handler function up and then point the iframe at our Shibboleth protected API CGI script. It will then do the 302 redirection chain to the IdP and possibly back to the API script and the iframe contents will end up as either a bit of JSON, or the HTML for the login error page from the IdP. In other words unlike XMLHttpRequest, the iframe behaves much more like the web browser session the user experiences.
Our onLoad() handler function can then use this to determine if the user is logged in to Shibboleth or not. There is one more “gotcha” though, and again its related to cross site scripting protection in browsers. If we get a resource in an iframe that comes from the same server as the page that the Javascript was included in, we can peer into the contents of that iframe using Javascript object calls. However if the iframe is filled from another server, our Javascript in the client can’t fiddle with its contents. There’s a good reason for this: you don’t want naughty people including your banking site inside an iframe and then extracting out your account details as you’re using it. This also applies if we request a resource from our server in the iframe but due to HTTP 302 redirects the final document comes from a different server (as will happen if a user who is not logged in gets sent to our IdP).
Luckily, in our case we’ve got one hack left up our sleeve. If we try to access the iframe contents that have come from the IdP (which isn’t the server we put in the src attribute to the iframe), Javascript in the browser throws an error. However we can use the try-catch error handling mechanism to grab this error. As it only happens when we’ve got a document that hasn’t come from our CGI API script (assuming our CGI API is hosted on the same server as the HTML and Javascript came from), then we know that at that point the user isn’t logged in with a Shibboleth session. We don’t need to see the IdP’s document – the fact that we can’t see it tells us what we need to know.
And we’re there! We can finally have client side Javascript that can deduce whether or not the user’s browser has had any Shibboleth session with our IdP open and if so can find out what the cn or eppn for the user is. Just for completeness, here’s a test HTML document with embedded Javascript to show that this works – you’ll need to serve it from the same web server as the Perl API CGI script above and modify the iframe.src accordingly.
<html>
<head>
<title>Javascript playpen</title>
</head>
<body>
<button type="button" onclick="checkIdp()">Test against IdP</button>
<p id="response"></p>
<script>
function IsJsonString(str) {
try {
JSON.parse(str);
} catch (e) {
return false;
}
return true;
}
function checkIdp() {
document.getElementById("response").innerHTML = '';
var iframe = document.getElementById("iframe");
if(!iframe) {
iframe = document.createElement('iframe');
iframe.id = "iframe";
}
iframe.innerHTML = '';
iframe.onload = function() {
var iframe = document.getElementById("iframe");
try {
var text = iframe.contentDocument.body.innerText ;
} catch (e) {
document.getElementById("response").innerHTML = 'Not logged in';
return;
}
if(IsJsonString(iframe.contentDocument.body.innerText)) {
var res = JSON.parse(iframe.contentDocument.body.innerText);
document.getElementById("response").innerHTML = 'Logged in as ' + res.cn;
} else {
document.getElementById("response").innerHTML = 'Not logged in';
}
};
iframe.hidden = true;
iframe.src = "https://www.example.org/cgi-bin/ssocheck/whoami";
document.body.appendChild(iframe);
iframe.src = iframe.src;
}
</script>
</body>
</html>








{kind=link}